Theoretically, the model would work on any image resolution. The model doesn’t process the whole image at once. It looks at a small part of the image through the receptive area. Then the system moves the receptive area in some direction (depending on what the model saw).
So, theoretically, the model doesn’t have to even examine the whole image. Only parts, which the network considers important for recognition.
But my program is not perfect.
Until some point, I didn’t think that idea would work at all (I was developing it for my graduate work, actually). Then I was curious to see if the model would work on all range of “human” tasks. But I tried to make tasks as simple as possible to debug the program.
About half a year ago, I decided to use MNIST dataset to compare results with results of “narrow” networks. Appears to be that my program is very unoptimized. And the algorithm contains couple fundamental errors, that doesn’t allow it to normally work on big data.
That’s not the restrictions of the model, that the limitations of current program realization.
That’s not much to look at.
MNIST image. Scanning window moves through the image. A log of answers, error rate. I didn’t test on the whole MNIST dataset, so I can’t compare results.
Do you still want the video?
The strong part of the model is not a classic ML tasks. The main advantages of the model are:
Universal architecture. We don’t have to change the algorithm or the architecture for the specific task. And the model can combine very different types of tasks in one network, like driving a car, talking and playing chess (for example).
Ability to perform most of the tasks, which currently considered only possible for a human being. Like logic games and tasks, which requires understanding, thinking, imagination, and creativity.
@stepan yes i really need a Video for better understanding your algorithm, which contains input images(MNIST, or human faces etc.), an Images your also Sees/interpretes, a predicted image and classification results.
You said your algorithm look at only a small part of input image at a time instance. How many steps it needs for processing the whole image? How can it move from one part to other parts of the image? Columnwise? Randomly?
Ok, here is a short video https://youtu.be/rclxScVO_do. The images are from MNIST (scaled-down a little). There is no predicted image (at least I didn’t see the point to extract it).
I mentioned that the network doesn’t have to process the whole image. Are you asking about how much steps (moves of scanning window) till the result?
I don’t know. It’s not predefined. When the network associatively activates action “to type the letter N”, then will be the result.
Practically count of steps very depends on the way how to train the network.
The neural network moves the scanning window itself. It learns to do it the best way. The network associatively activates action “move in direction M” when it needs to.
It’s move based on what the network saw and did (the context) and what it sees on the current timestep. So, the sequence of moves can be different for different images.
Eventually, it finds the way to features (or sequences of features) that uniquely identifies the object. By the way, an empty space is also a good feature in some cases.
Please, don’t beat up my poor example too much. That’s very unoptimized program.
But I still think the model has potential. How about you?
How can the model be empty and also know to look for another feature of the object?
So your theory must incorporate rotation or egocentric location somehow as well. I would be interested in those mechanisms. We think they must exist also, and they are non-trivial. How can this happen in your model without layers?
It seems to me after reading your text that there is a location signal in your model, you just have a way of generating it via movement vectors. What I don’t understand about your model is this… if the model has an object under scrutiny and you command a sensor to move to a location where it has sensed features of the object before, can you extract the predicted sensation before it occurs? Can you get the predictive state of the neurons that represent the sensation on the object before touching it just with the movement vector?
I still don’t see how this model brings everything together without neurons having a predictive state caused by distal stimulus.
About hierarchy… Numenta’s current sensorimotor work has no hierarchy, we’ve found out that cortex is doing a lot more within a region than we expected. It looks like from your drawings and explanations that you consider each level of your neural network model to be a layer of the hierarchy. So each connection from one neuron to another is a hierarchical jump. Is that correct?
In summary, my observations lead me to believe that you are trying to build a more standard ANN model without explicitly using an HTM Neuron, but exhibiting all the properties of HTMs you listed in your first post. You depend on hierarchy for object recognition. Am I characterizing your system properly?
It is really very difficult to understand how does it move at the beginning because there is no neuron before. What is happened if it sees an eye first time? How does it know to move to find the 2nd eye? Why the 2nd eye? Why not nose or other part of face? What is happened if the 2nd eye is not found or existed? And more questions…
Thank you, Matt, for trying to understand my model. Most scientists usually ignore what’s different from their work.
I really think that the HTM could be improved by applying some results of my research.
Let me start at the end of your reply:
When we go up or down - yes, definitely.
Neuron O1 represents pattern (I1, I3).
But pattern can consist of neurons from different levels of abstraction.
So the hierarchy is very “blur” and “crooked” here. But surprisingly flexible and effective.
Yes, you are right. I built an ANN, which doesn’t use the HTM Neuron but doesn’t use the McCulloch-Pitts neuron either. I think the neuron more like your “cortical column”.
Recognition is possible without hierarchy, but, in that case, it’s more like one-step classification.
In the beginning, the network consists of zero neurons. As you noticed, it can’t do moves. The model doesn’t know how.
But we need the network to do some task (for example - visual recognition). So we force the network to make some random move (forget about “reflexes” for now, they’re mostly for automation). The network will make a new neuron O1 from currently active neurons:
Look on fig A. R1 is a neuron, which activated by the receptor from the receptive field. It’s active because the network sees a dot in the receptive field.
M1 is a neuron representing “acceptor” (is it a right term?). When M1 activates, the system moves receptive field (let’s say it moves right).
Current input (M1 and R1) connects through new neuron O1.Thus, now our network consists of 3 neurons (R1, M1, O1). Now, it will be able to do “move right” by activating neuron M1.
Fig B: when the network sees a dot in the receptive field - that activates neuron R1. Neuron R1 activates neuron M1 through neuron O1. O1 represents a recognized pattern and will become the context for the next timestep.
Further, we could train the network to make moves in other directions. If we need it to do additional tasks, we can teach the network to “type a letter”, or “draw a dot”, or “move an arm”. This approach makes the model very flexible.
About how the model finds the feature on the object and why - see in my next reply to @thanh-binh.to (his question was right after yours).
Nope. Still no separate location signal. Only associative activations. But those associative activations are non-trivial indeed.
Let’s look at the pictures:
The second figure is clearly a rotated number “four”. But how did we recognize it?
There is actually more than one way to create necessary associative connections. The model would be able to generalize if we teach the network to rotate its receptive area (like we can tilt our head to see if the picture is the same).
But I want to show another way, associative connection through words (do you remember that I tested the program on “visual recognition + text dialog”?).
The activation of the same words allows the network to connect visual representation (generalize). Here and there is very similar sequence: “ending of line” → some move → “angle” → etc.
Unfortunately, the scheme of neural activations for this example is very complex. Every word, every sentence, every picture is a sequence of patterns. On every timestep - multiple activations of associated representations.
Fortunately, you don’t have to understand how it works to train the network. You can train it the same way, how you would teach a child.
By the way, look at those pictures:
Here you clearly see a rotated letter “h”, aren’t you? But the picture is the same. That’s the importance of context.
If I still need to explain how works the recognition of rotated objects, I’ll try to come up with simpler example and draw a scheme of neural activations.
In my opinion, more interesting to see how the network can answer abstract questions. The mechanism is very much the same. How do you think?
Movements are an output. But they also are an input. For the network, that’s no different from seeing an image.
Recognized an “eye”. Neuron R1 represents a pattern “eye”.
Neuron R1 activates neuron M1, which makes the system “move right”. Neuron O1 represents a sequence of patterns “saw an eye, move right”.
Recognized an “eye”. Neuron R1 activates again, but now in the context of O1.
Neuron O1 tried to activate again to make move “right”, but it was inhibited (the inhibition process didn’t show in the picture). But neuron O2 (in context of O1) activated M2 (move “diagonally”).
Thus, there is no separated “movement vector”. Movements play the important role, indeed. But if I demonstrate the network this sequence of pictures, one by one:
The network could recognize this sequence as a face, even it didn’t move its receptive area.
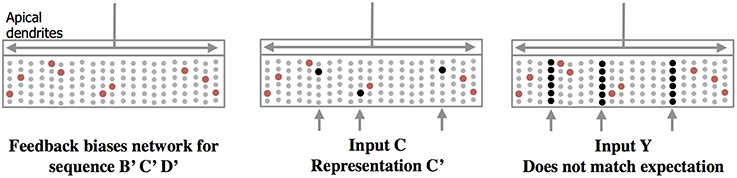
Prediction is very important part of my model. Let’s look at the picture (from the paper):
Now, let’s look at the scheme of my network for the same task:
Your model predicts next input B after A. It depolarizes B’, makes it easier to activate.
My network reaches the same effect. The recognized representation O1 makes easier to activate representation B’, which represents the sequence: B activated after A.
Next letters go the same way.
But I think your approach has a serious downside. In real life, we never receive the exact same pattern twice (pattern of signals from all of our receptors).
In our speech, we can skip some letters, talk faster or slower, with an accent or not. Same applies to every other task.
So if we put sequence “A_CD” instead of “ABCD”, I suppose your model wouldn’t be able to recognize it. Would it?
My model can recognize such damaged sequence, but, if necessary, we can teach the network to perceive “A_CD” as a completely new sequence, different from “ABCD”.
I suppose, your model assumes that the brain has some sort of “hardcoded” mechanism to compare patterns (and SDRs). Am I right?
But there is enough evidence that humans can’t compare object from the birth and learn to do it. I’ll get some examples, if necessary.
And the same patterns could be perceived differently under different circumstances (in a different context).
I would be glad to propose some improvements of the HTM for your consideration. What do you think?
@thanh-binh.to, you’re asking the very important questions about visual recognition task. Do you work on visual recognition tasks yourself?
Basically, we have three ways teach the network initial abilities:
Force the network to do specific moves until it learns to do them itself. That’s the fastest way to train the network but requires constant supervision at the beginning and deep knowledge of how the network should work.
Make a set of simple reflexes. For example. reflex, like “if it doesn’t make any moves - force it to make move in the direction of highest density”. This approach gives some automation but very much depends on the set of reflexes.
Simply make the network to do some random move or to give an output, if it doesn’t do anything.
I think humans have some set of reflexes that allow them to get initial skills. But I don’t know the what those reflexes are.
So, I usually use simple set. The set gives to network positive feedback if it recognizes object right and negative if it gives the wrong answer or no answer for a while.
It memorizes the input visual pattern, the context, the move or answer and the feedback.
The network sees an eye. If it previously moved “right” (randomly for example) and successfully recognized the object, the network will move the same direction again.
If the network recognizes the object wrong, it probably will try to move in some other direction, which it didn’t try before. Or try to look further. Really depends on the set of reflexes and previous training.
The network tries to find feature or sequence of features which strongly defines the object. Because this feature will be giving it positive feedback. If the network finds such feature, it starts to go straight to this one.
An eye was just for example. Really depends on a task, set of reflexes and dataset of objects.
In some tasks, it would be the strong feature. Like if we distinguish one-eyed man from a man with two eyes
If it leads to positive feedback then the network just “imagine” an eye and continue to recognize the same way. If it leads to negative feedback, the network starts to look for an additional feature.
Practically, if some part if the image allows to definitely exclude even one possible answers, it worth look into.
The real deal is how the network propagates the feedback on actions, which lead to this feedback.
Like if your dog peed on the carpet but you noticed only an hour after that. How would the dog connect pee and your being mad?
In my model, it goes through self-evaluation mechanism. The network gives feedback itself, based on its experience.
Stepan, I appreciate your response. I want to take my time reading it and responding. But this week is really busy. I will come back to this, ok?
One thing though… your impression of HTM here is wrong. It certainly can recognize it. And it certainly will learn it as a new sequence if it sees it enough. This makes me think you don’t have a full understanding of HTM. In fact, many of the attributes of your model you’ve promoted are also things HTM currently does today. Have you read our papers or watched HTM School?
Matt, I really enjoyed your HTM School videos.
Maybe I got something about HTM wrong, maybe I just didn’t explain differences clearly. I would love to look into things, which, in your opinion, I didn’t get.
About this example. I really appreciate your time. Sorry, but I still don’t understand. Please, explain it to me when you have some time.
How I thought the HTM would work in that case:
The network sees input A. It predicts input B. So, B’ become depolarized.
But on the next step, the network receives unexpected input (in this case - it’s empty input). But there are no cells to become active indicative of an anomaly. So it just stays the same. Like in this example, when it gets unexpected input.
B’ is just depolarized (by the way, for how long?), but it can’t be activated without an impulse from proximal synapses. Thus, no one could activate C’. And the next input C become unexpected and all cells in the columns become active indicative of an anomaly.
So as D’ can be only depolarized by C’. But C’ is not currently active. Isn’t it?
B’ would typically be depolarized for one time step
Technically C’ is active in this scenario (along with C’‘, C’‘’, etc). Some of the bursting cells in the C minicolumns are the cells which represent C’. Thus, the cells for D’ are now depolarized (along with any other inputs that might come after a C in any learned context). If D is input next, the error is corrected, and the future inputs in the sequence once again become predicted.
A single error in a learned sequence (for example a skipped element in the sequence as you have described here) results in bursting which quickly corrects itself after the next input or two (assuming they do not also contain errors). This is because bursting columns cause all learned next inputs to become predictive, so the following input should match one of those possibilities. If learning is enabled and that same error occurs enough times (depending on the configuration), it will no longer be considered an error and it won’t result in bursting any more. Eventually if the same error happens frequently enough and the original doesn’t occur any more, the “error” will become the only prediction (original will be forgotten).
Thank you for the great explanation. Clearly, I was mistaken.
The HTM can perform this task not worse (and probably even better) than my network.
Can I ask you another short question?
How would the HTM imply such cognitive processes as thinking and imagination?
An example:
I see a door. Let’s say I want to open this door for some reason (maybe that’s a sign “Candy store” on this door ).
But the door is locked. I see a big lock on the door. So I start to think.
To open the door I need to unlock it. To unlock it I need the key. The key could be found under a stone near the door or may be on the door.
So I start to look in those places. And maybe even find the key.
This task requires “imaginary” input. So the network could process patterns it doesn’t actually see at the moment.
The HTM doesn’t activate the predicted patterns if it doesn’t actually see it (Am I mistaken again?)
How would the HTM solve this task without those “imaginary” inputs?
I’m paraphrasing from Jeff Hawkins here, but I can add some detail to this.
I always teach that proximal input is required for HTM Neurons to fire, but this is actually not always the case. There are circumstances when some combination of distal and apical input will cause cells to fire without any proximal input. These are instances of imagination, when patterns are being “played back” through the feedback coming from apical connections, whether they originate in higher layers in the cortical column or from higher regions of the hierarchy. Imagination of an action activates the same (or very similar) neurons as the actual performance of the action, but they don’t receive proximal sensory input because action was not taken.
I think that particular example is in the domain of a hierarchy which unfortunately HTM doesn’t currently have, but I can walk through how I picture it working though.
Lets say you have a sequence somewhere in your hierarchy that represents “Eat candy!”, which has a large reward associated with it. This sequence is being predicted due to features that are being sensed and represented in more abstract higher levels of the hierarchy (the sign with the words “Candy Store” in this case).
Because you have had semantically similar experiences in the past (such as other stores you have visited), you are predicting that there is candy located on the other side of the door. Your reinforcement systems are predicting good reward if you can get to the candy, and significant punishment if you are caught breaking in. Lets say the reward outweighs the punishment and so you decide to go for it.
The abstract “motor” sequence you are predicting now is “Open the door” -> “Get the candy” -> “Run!”.
Variations on the “Open the door” sequence might include “Open an unlocked door” and “Open a locked door”. Features of this door that are being sensed (the big lock) narrow that down to “Open a locked door”.
Lower in the hierarchy, the motor sequence “Open a locked door” might break down into “Locate the key” -> “Unlock the door” -> “Open the door”. Feature “Locate the key” might be further narrowed down to “Check under the rock” based on the rock that is being sensed in this scenario.
Even lower in the hierarchy, a feature of “Check under the rock” might include “Reach out hand”. A feature of “Reach out hand” might include “Flex bicep”. The basic idea is that “motor commands” in higher levels of abstraction unfolding down the hierarchy, eventually becoming low-level actual motor actions.
Now I realize that doesn’t directly answer your question about how “imagining” might be addressed by HTM, and that is really because it isn’t currently. The brain definitely has the ability to manipulate thoughts in a way that is much like taking motor actions. I suspect these are just applications of the basic SMI functions, only in a more abstract space, but we probably won’t really understand this until we are able to model very deep and complex hierarchies at some point in the future.
Your replies were great and cleared a lot about how you think the HTM would process hierarchy.
But seems like no one has additional questions. And I have failed to capture your interest
So, final thought. I want to point on some weakness of your approach.
Please, don’t be offended. In my work, I tried a lot of approaches. Most of them seemed very promising but didn’t be able to perform all “human” tasks. Therefore, I have big experience in failures.
The theory may seem fine, while you just thinking about it. But when you actually try to put your theory into a program and test it on real-world tasks, you likely going to encounter some problems.
Problems with fixed hierarchy.
In your model, you probably won’t be able to use high-level representations in current sequences. Look at the picture:
Your model wouldn’t be able to predict “red signal” after it sees a banana if it was trained on an apple.
Maybe, if the red signal would make representation on the same level as “fruit”, the HTM would be to predict it. However, when the model sees the red signal for the first time, it definitely doesn’t have high-level representation for a “red signal”.
Apple and banana are very different visual patterns. But even a monkey could easily do this task by only one example.
Real-world tasks usually require combining multilevel representations in one pattern. And do it instantly.
Problems with generating this hierarchy.
Frequently similar patterns can have a very different meaning. And very different pattern - mean the same thing.
If you use unsupervised way for high-level representation generation (and seems like you’re planning to do that), you going to have real problems with the program when it comes to real-world tasks. A teacher and the model itself should have control over generalization process.
My model gives an easy and universal way to make necessary generalizations both ways: “supervised” and “unsupervised”.
Problems with actions.
About two years ago, I tried this architecture:
At some point, it’s close to your description. This architecture is quite good for recognition. But recognition without an output is useless. The program has to learn to do some actions.
I’m still confused about how you’re planning to teach the HTM to do that. For general model, actions cannot be hardcoded. We learn how to act, to talk, to think.
The HTM would easily detect an anomaly in sequence A, B, C, D, etc. But what if the task would be to say the missing letter when the model detects it? Or to wave a hand when the program notices the anomaly?
Problems with projecting experience.
On real-world tasks, we can’t teach the model every possible case. It has to be able to learn by just one short explanation and project its knowledge on a new task.
For example, let’s look at the task: “Counting letter in a sentence”.
First, we have to teach the model to do the sequence of numbers. 1, 2, 3, etc. The HTM would easily recognize and predict this sequence, but about output… Let’s assume we somehow managed to teach the HTM actually say those numbers.
Second, we have to teach it to count specific letter (e.g. “a”) in a sentence (e.g. “abcdbca”). The model has to say “1” when it encounters first letter “a”. But then it should keep it in memory until the model encounter second letter “a”. And then say “2”, etc.
I guess you would have a hard time to make your HTM program to do even that.
Then third, we have to “explain” the program how to count different letter “b”. Not retrain for a different pattern. Like, I don’t think I ever counted letter “q”, but I would easily do that without specific training.
For “projecting”, the model has to keep active what it did to “a”, but project this knowledge on “b” and ignore “a”.
My model uses dynamic representations and a context to do that. I suppose the HTM with its stable high-level representation would have some difficulties.
That’s really sad to see how you “narrowing” your great and general model by trying to put hardcoded “location signal” in there. This approach can show very good results on specific tasks “recognition of a small set of objects”.
But “On intelligence” book postulated “simple and general algorithm for all regions of neocortex”. And now you’re creating “narrow” program with a location signal, which would probably be useless for tasks different from recognition.
There is a simple and general way to do robust recognition without this thing. Why wouldn’t use it?
I don’t say your approach doesn’t work. It definitely does. But that’s not enough, the general model should provide an easy and universal solution for any intellectual task that a human being can perform.
For the past three years, I tried a lot of different approaches. Most of them work for some limited set of tasks, but I was always able to find task the approach would fail on.
The HTM is great for low-level representation. The results of your model are remarkable. But apply your current program to perform high-level tasks will be a difficult task.
On the other hand, I started with high-level tasks. I modeled consciousness. I already faced and solved most problems you only going to encounter. My experience could save you a lot of time.
Now I have a program which tested on a wide range of human cognitive abilities. To debug the program I had to figure out how exactly our consciousness works for every specific task.
The program uses such cognitive processes as “understanding of the meaning”, “thinking”, “imagination”, “creativity”, “projection of experience”. And the program can be trained the very same way as you would teach a child.
Unfortunately, for all tasks, I only checked if the network able to perform them. After a long development process, the program is quite messy. It contains parts of previous approaches, which didn’t work. A while ago I made couple fundamental mistakes in the algorithm, so now the program is very limited. I know exactly where this errors, what influence they make and know well enough how to fix them. But for now, the program can do every “human” task only in “simplified” way and fails on a big data.
For me, it would take at least half a year to rebuild the program. But I’m pretty sure that together we could make a cool prototype in a few month. The program is already can make conversation, play video games, create paintings, etc. The only problem is the amount of data it can handle.
Don’t you want to have the general AI right now and not “at some point in future”?
I would be happy to provide any additional information you may request.
Although, I’ll understand if you don’t want to waste your time and effort. You have the HTM.
So, how about you help me to publish some of my work and we both see if it worth the shot?
What would you say about that?
We have been working really hard to get our own work published for the past several years, and we are still struggling to keep up. As fast as new theory is being developed, we can hardly keep up with our own publishing.
I always want to encourage people to work on HTM-related problems even if it is tangental. Please don’t take my lack of action as lack of interest. But we simply don’t have the bandwidth to investigate every alternative theory out there completely. There is a lot of potential, but we must focus on our own work. I hope you understand.
For me at least, I am deeply invested in my own implementations of HTM, and using those to explore various problems, so it is difficult to break away and start with a new core AI algorithm. It is possible that I will reach a point in the future where I can’t expand any further with just HTM concepts alone and I’ll have to start exploring other approaches (but that day is not currently anywhere in sight – HTM has enormous unexplored frontiers to expand into at its current stage).
I think of hierarchy solving this problem in a bit different way. You don’t want a banana to be predicting a red signal, since a banana is not red. Where hierarchy helps solve this particular problem is by combining spatially separated inputs (physically different populations of cells) into representations that preserve their semantic similarities.
In the case of fruit, when you are being “trained” on an apple in the real world, you are getting low-level inputs like: “red signal”, “sweet smell”, “smooth skin”, “hard stem”, “thin skin”, “sugary taste”, “hunger satisfied”, etc. You are also getting a bit higher-level audio input for worlds, like “Fruit for sale!”, “Here, have an apple.”, etc. And higher-level visual input, such as signs that say “Fuji Apples”, “All fruit is on sale!” etc. These are all activating populations of cells in the brain that may be physically very far apart from each other.
If you roll all these lower-level inputs up into a pyramid-shaped hierarchy, then physically far apart representations can now become features of more abstract representations of “apple”, “fruit”, etc. These representations serve to establish semantic similarities between objects lower in the hierarchy, by creating SDR representations for them that have varying amounts of overlapping bits.
Now bring the new, novel banana into the picture. It comes with some of the same low-level inputs as the apple did, such as “sweet smell”, “smooth skin”, “sugary taste”, “hunger satisfied”. It also has some of the same higher-level audio input, such as “Fruit for sale!”, and higher-level visual input such as “All fruit is on sale!”. This smaller subset of the same inputs will traverse up the hierarchy as they did for “apple”, along with some new inputs, such as “yellow signal”, “soft stem”, “thick skin”, “bananas for sale!”, etc.
As a result, the representation generated higher in the hierarchy for the concept of “banana” will include some overlapping bits as the SDR for “apple”, but will also have some of its own new bits. Some of the overlapping bits for “apple” and “banana” will also overlap with the SDR for “fruit”. These high-level concepts can all exist in the same level in the hierarchy (i.e. “apple” and “banana” don’t necessarily have to be lower in the hierarchy than “fruit”, they just need to be able to share the proper percentage of overlapping bits to represent their semantic similarities, which means those representations need to be spatially near to each other)
The way I see it, the example of “Bat (animal)” versus “Bat (baseball)”, the word “Bat” could have an SDR with a percentage of bits that overlap with the SDR for “Animal” and a percentage that overlap with the SDR for “Baseball”. Therefore, the word “Bat” becomes a shared feature of the two concepts “Bat (animal)” and “Bat (baseball)”. In this case, hierarchy would be used to bring together spatially separated inputs, like the feeling of fur, the shape of a bat, the sound of a crowd cheering, etc. in order to create the representation of “Bat” which encodes the proper semantic relationships between those various lower-level parts. This “feature” can be used in various abstract “objects” higher in the hierarchy, such as “Take me out to the ball game”, or “I’ve come to drink your blood”.
In order to have a working SMI implementation, it requires reinforcement learning. Actions are learned through reward and punishment. I have no doubt thatI suspect that Numenta will be tackling RL in the near future as part of their SMI research. This is an area that several folks on the forum (including myself) are actively exploring as well.
This one is a bit more complex, but I don’t really see hierarchy being the go-to solution for it either. In this case we are asking the system to count occurrences of a particular letter. The system would first need to have an idea of what “counting” means (I would argue that there is a lot more to counting than just memorizing the sequence “1 2 3 4 …” – it also requires abstract concepts of numbers themselves). Then we also need a way to tell it what letter to count (meaning it needs to be intelligent enough to understand English or at least some low-level system of commands). Ultimately, the sequence being learned is not “a - 1, a - 2, a - 3…” and projecting that to “q - 1, q - 2, q - 3”. Rather, it is “subject - 1, subject - 2, subject - 3”, where “subject” is the thing that the system was told to count.
Of course, I am being rather vague here, but my point is that a task like this seems to me that it would require a far more robust hierarchy than it might seem to from the surface. You are basically describing the concept of imagining one abstraction in terms of another (which is something that even modern hominid species didn’t do very well, as evidenced by the stone hand axe which didn’t change for nearly a million years prior to the emergence of our species).
I think this is more a means of focusing the research on other areas, rather than the end goal. When your working out the individual elements of a system, you don’t usually start out by developing everything all at once. Instead, you hard-code some elements so that you can focus on others. Eventually, you go back and revisit the things that you have previously punted.
@dwrrehman has posted some of his ideas related to the “location signal” as well. The representations of “location” can in theory be derived over time by distilling semantics from patterns of input and motor actions over time. In my opinion this is really the only definition of “location” that makes sense in the abstract space, for example (IMO grid representations only really make sense for spatial concepts like “my position in the room”, etc.)















 ).
).







{kind=link}