Hi @steinroe.
I actually implemented a Multivariate Anomaly Detection (with 1 single model), and the results are pretty encouraging. The code is still messy (need to do some refactoring). Here is what I did: https://buttignon.next-cloud.org/index.php/s/D9CJmGMoADB56rd
2 Likes
Hi @pizzatakeaway,
thanks for sharing!! Would it be possible to share to whole document? I would like to cite it in my work 
Best
Philipp
2 Likes
Hey @steinroe, so I have my own python module which builds multiple NuPIC anomaly detection models from multivariate time series.
It samples the first N rows to calibrate the encoders, then instantiates the models, applies them to the rest of the rows and saves them to disk. This yields a separate anomaly score for each field (csv column) at each time step, which can then be combined, thresholded or otherwise analyzed.
I made it for my own research involving n-dimensional movements but generalized it with a config file, so you give it the file paths, N first rows to sample from, whether you want 1 multivariate model or multiple univariate and a couple other things.
Right now I don’t have it shared on Github, though if you’d like to test it out and would cite the repo I’d consider sharing it.
Also @pizzatakeaway (funny handle), I glanced at your work and noticed this:
the algorithm was not able to tell which feature was responsible
I think the multiple univariate model approach should help with this, since you get separate anomaly scores for each model at each time step.
Also have you seen NAB (Numenta Anomaly Benchmark)? In case not I’d definitely recommend checking it out. Its purpose is to test HTM against other anomaly detectors including Etsy Skyline and Twitter ADVec across a range of data sets from numerous domains. I don’t think it includes RNN or LSTM as you do though. The code actually has a ‘create_new_detector’ script too, so you could potentially plug in your RNN or LSTM detector to it. That’d allow you to quickly test those or any detectors over like 55+ data sets, which already have labeled anomalies and built-in detector-scoring functions.
1 Like
@steinroe sure, here is the whole document: https://buttignon.next-cloud.org/index.php/s/a52D5bxBSMKqSNn
@sheiser1 Nupic or multiple univariate model if you prefer call it that way, it has been outperformed by a multivariate HTM system in the experiment I run. Why? Because the algorithm benefits from the correlations in the data. The ECG Experiment (the first one) shows it clearly. Nupic recognizes the anomaly on the 1st signal, but not on the second.
Furthermore, reading at glance misled you. The Feature Importance method worked very well.
The meaning of the whole sentence was:
So far, performing multivariate anomaly detection with HTM was possible but incomplete.
The algorithm was not able to tell which feature was responsible for the anomaly, and to
which extent.
1 Like
NAB is a great tool, but there are only univariate datasets to be found.
In try to find multivariate datasets e.g. the Damadics dataset cited by Subutai at the end of one of its papers in the Future Works paragraph.
On multivariate datasets I applied Nupic (I called it uHTM that stands for univariate HYM), Etsy Skyline and Twitter ADVec on each signal singularly: I loaded each time series on NAB and let the script do the threshold fine tuning.
1 Like
Makes sense yes, I’ve experienced this also. I think the single multivariate model approach is better for this reason, as long as there aren’t too many variables to squeeze into it.
I’m glad to hear it! It makes me curious, if the algorithm “was not able to tell which feature was responsible for the anomaly”, how were the features measured for importance?
Yeah most probably. It should be researched further. I stopped to 6-7 variables (6 was semi-supervised, 7 unsupervised).
For example, in this experiment (ECG Fibrillation), 2x univariate HTM has been applyed the two channels.
According to them, only in the first channel the anomaly was correctly detected, and not in the second.

Actually was pretty simple (once I realized it), I expained it in 4.4 and you can see it in action in Chap 5.
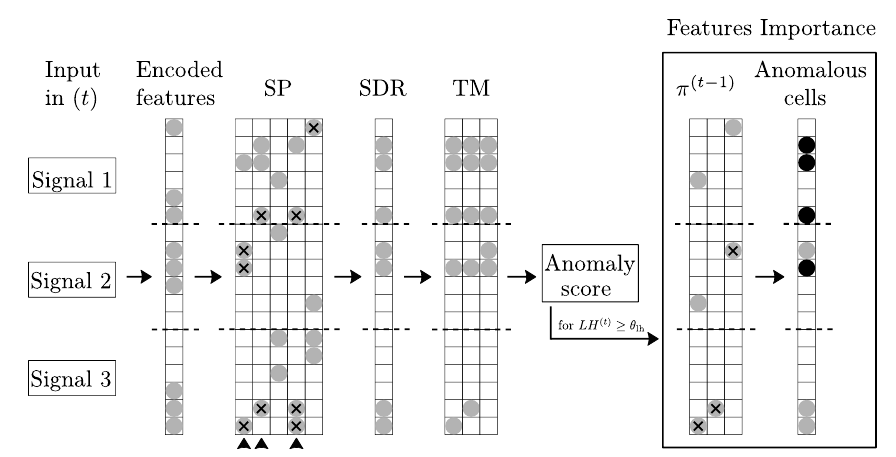
To work with multivariate time series, we need to encode every single feature and stack the single encodings upon each other to form the binary input vector. The key is to keep track of the indices —x_i to x_j— of the single encoding vectors.
When the input vector successively enters the SP, even though the active bits change as shown in the Fig, the c_ij cell in SP is always representing the x_i cell in the input SDR.
Therefore, we can travel back from TM to x_i , and identify to which encoded feature x_i belongs to. For the same reason, moving from the SP embedding to the TM embedding is possible without losing the traceability of our input x_i.
In the next step, the AS retrieves from TM not only the information about how many active columns were not predicted, but also which ones. When the anomaly likelihood for an instance, exceeds the threshold θ_lh, we use the indices of the active not predicted columns to access the input vectors. Finally, by counting the overlapping indices with each input vector, we calculate which features caused the anomaly and to which extent.
1 Like
@pizzatakeaway for ECG AD there is another method for classifying QRST pattern so that you can classify SDR as anomaly. I am very interested in knowing how better your method is than using SDR-classification.
Do you have any comparison result? Thanks
Hi @thanh-binh.to, here is all I got: https://buttignon.next-cloud.org/index.php/s/a52D5bxBSMKqSNn
There is code and more graphs, but the repo is not very user friendly at the moment 
@pizzatakeaway what do you mean „code“?
Your algorithm description? Or SW code?
@pizzatakeaway: I am very interested in how you do your experiments with mHTM and LSTM for each data in datasets:
- Do you train LSTM before? or
- do you run both HTM and untrained LSTM and consider AS they output?
- or train them from T=0 till N, I say N = 1000 ECG-points and after that turn them to inference mode for AD for all remain ECG points?
Thanks
1 Like
@thanh-binh.to hi again
LSTM has been implemented according to the architecture presented in the paper of Malhotra et al. 2015.
- Yes. In the graphs there is a gray shaded area. This area represents the evaluation set and it divides the training from the test set. In the training and aevaluation set there are no anomalies.
- for HTM it means I use the training set to feed the LH. Of course I wait for the AS to settle down.
- The learning modus by HTM is always on.
Results and evaluations are only take the TEST set into account.
Did I answer your questions properly?
1 Like
I mean the Python code I wrote to implement the feature importance method and run all the experiments presented in the paper.
1 Like
Ah I see, that’s great!
So you keep track of which encoded features all the SP columns represent, then you can see how much each feature contributes to each anomaly score above 0.
Do you have this implemented using NuPIC models?
@pizzatakeaway thanks for your answer! I am not sure if the results are comparable, because HTM is always On so that it learn too the abnormal QRS pattern!
Please correct me if I am wrong. I think, each data has 2 parts: training and inference. Both HTM and LSTM learn only with train part and than turn to inference mode for anomaly detections!
What do you mean with NuPIC models?
1 Like
I mean how did you generate your HTM models? Was it with NuPIC or some other framework? Or you own home-built version? I’d love to see how you implemented the feature importance system you eloquently presented there!
Sure… it is one of the “downsizes” of HTM. They can learn new patterns but if anomalous patterns are recurrent, they end up with learning them.
On the other side we can philosophize on the meaning of “anomalous/anomaly”: if an anomaly is recurrent, is not an anomaly anymore but rather an unwanted behavior. In this case HTM as it is now, is not the go-to algorithm.
Concerning your question:
- TRAIN + EVALUATION SET (normal data)
- HTM (
learn:on): AS decreases, at some point we start feeding the LH and the Threshold is set - LSTM: try to learn by minimizing the loss function. The prediction errors are used to feed a multivariate Gaussian. Here the LH corresponds to the logarithm of the Probability Density Function (PDF) derived from the multivariate Gaussian distribution. The Threshold is set
- TEST SET (normal data + anomalies)
- HTM (
learn:on): LH evolves with the AS - LSTM: LH is dynamic (feeded by the Prediction errors)
Ok, I got it now.
I used the Nupic functions yes! Scalar Encoders, SP, TM and LH.
I just played around with the, LH, AS and the information that are also available in the verbose results: which cells were predicted in (t-1) which are on now in (t) and which are the unpredicted cells in (t).
Combining this last info with the indexes of the input vectors did the magic.
1 Like
Hi @pizzatakeaway I came across this thread while searching for multivarite time series in htm and wanted to read your work. Unfortunately the links only lead to error messages. Is the work published in the meantime (could not find anything) or could you send me a link? I would appreciate it very much.
1 Like