Yep, the trickiness comes when you think about learning in a heirarchy (inference is the easy part), and you consider that many times you need to be able to distinguish between things like AB AB and ABAB ABAB, while not adding garbage that diminishes HTM’s existing ability to learn complex high-order sequences.
You can always add another layer to the heirarchy, but (this may just be a personal bias with no basis in reality) I think you should always be pushing concepts from higher in the heirarchy down to the lower levels as things are encountered more frequently.
Anyway, sorry, it seems I have managed to inject my favorite topic into yet another discussion… I really need to stop doing that and start more of my own threads
I think I understand quite well what it is that tickles you here… and we couldn’t reason much about sub-sub patterns and sub-sub-sub pattern if any such sub has to somehow be another cortical area.
my answer on this would be twofold :
first, I’ll ask whether that ability to split the thing anywhere is really a ‘core, simple’ mechanism, or something pretty much worked by the yet elusive front brain + working memory ? I mean, I can maybe look at ABABABABABAB as being (AB)* quite ‘naturally’, but for you to even begin talking with me about it being also (ABAB)*, you had to include spaces into your writing… I mean, I don’t know… brain could apply “Ockham’s razor” to that question consistently.
second, my intuitions on that subject are quite clear since I’ve read JH and learned about current HTM, but I cannot say I have been able to come with an actual implementation. So there’s still lots of room there, to maybe envision that the relation between first and second stage also allow some amount of fuziness… Or it could be that… yes, once you start to ‘perceive’ it as (ABAB)* then you see ABABs all the way, but for it to be (AB)* again you need to ‘switch’ something: There could quite believably be a back-and forth between such perceptions, related to your areas ‘voting’ on the question. In pretty much the same way, maybe, as when you see a vase, or two faces, in that famous picture, or whether you see a wireframe cube in orthogonal projection as viewed from ‘above’ or ‘below’…
I think I found why my TM is doing it! Basically I’m not doing total inhibition within TM columns. I’m activating all matching cells in each active column, and in order to qualify as ‘matching’ a segment just has to have enough potential synapses (those with perms > 0). Whereas in order to qualify as ‘active’ a segment has to have enough active synapses (those with perms > .21). I think this basically lets weakly connected segments continue to activate and make predictions. In the context of your neat example above, the 5th timestep activates only the top A-neuron (call it ‘A-1’), generating no predictions and leading to burst of the next B input. In my system I believe both the top and bottom A-neurons (A-1 and A-3) would activate, leading to a prediction of B-2 and no burst at the next B input. Does this sound plausible to you?
This can be seen in line 16 of this snippet from my runTM function, checking ‘numActivePotential’ synapses, as opposed to ‘numActiveConnected’ synapses. I could’ve sworn this is what it said in the BAMI pseudocode but maybe not.
If I’m right, I suppose that changing the ‘numActivePotential’ to ‘numActiveConnected’ should change this Anomaly flat-lining. I’ll give it a try. Thanks so damn much again!
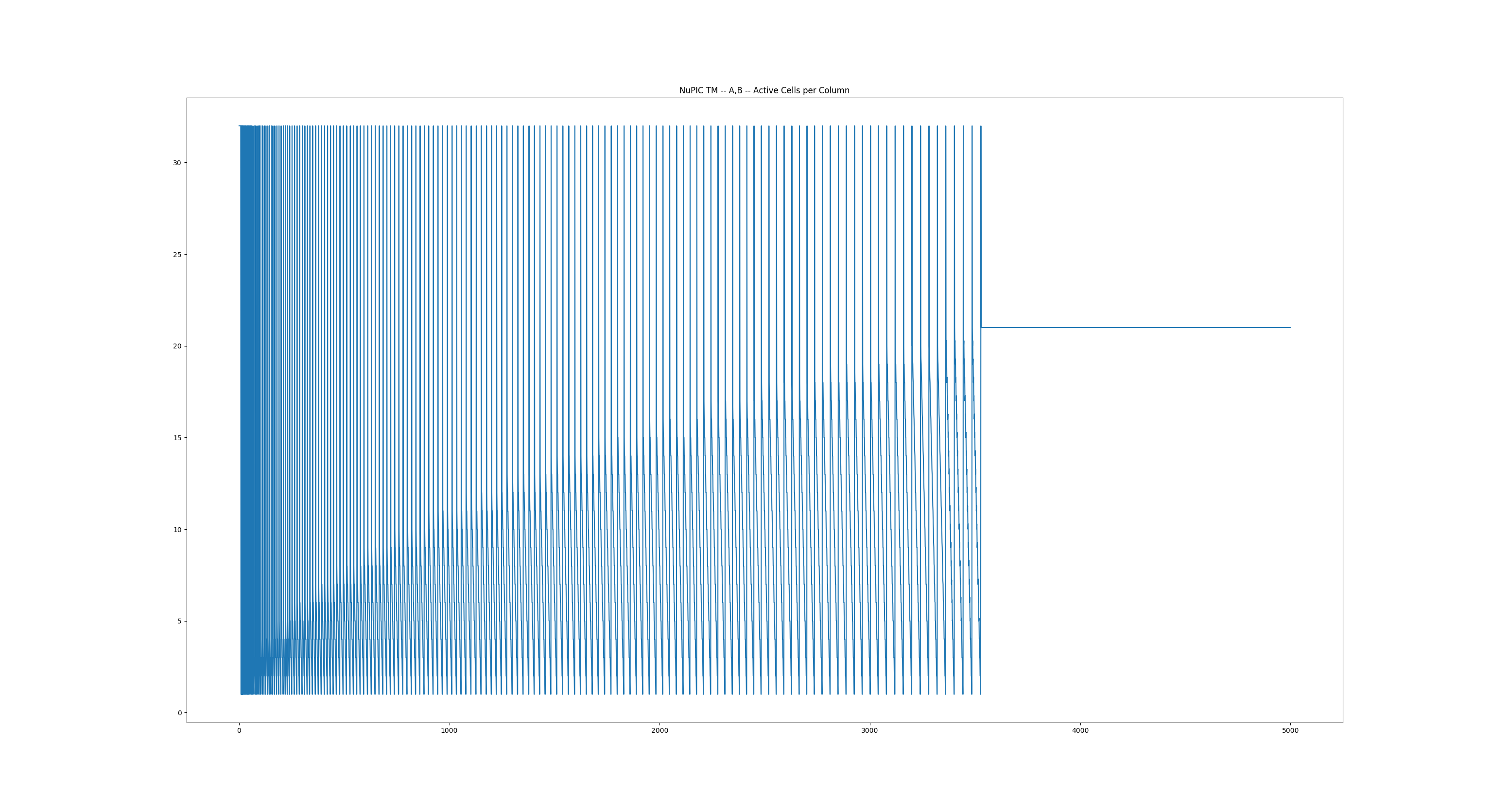
And here are the results from the experiment you recommended. I fed in the sequence: ‘A’,‘B’ repeating 1000 times. What I found is that when it eventually stabilized at Anomaly Score 0 (after ~125 repeats) the number of active cells per column also stabilized (at 11 of the 32 cells per column). I calculated this value by (number of active cell / number of active columns). Does this sound like a proper conducting of your test? Thanks once again
Perhaps, but that wouldn’t be relevant here though, because you are activating all of the distal segments very frequently. Every time it reaches the end of what it has learned up to that point and the burst occurs, it then cycles through all of the dendrites that have formed so far (see my visualization above). As long as you keep repeating the same sequence in a loop (which @sheiser1 is doing in this test), then nothing would be culled.
And even if the sequence were long enough and there were sufficient cells per minicolumn that the sequence took enough time to cycle through for this culling to begin, new segments would just be grown to replace any that were culled, because the algorithm is designed to use the full capacity of the layer (it always picks a cell with the fewest segments to grow a new one when a burst occurs, and the burst always occurs when it reaches the end of what it has learned up to that point).
Maybe this could cause the behavior you are seeing, but I am having some trouble visualizing how this would behave over time (I’ll probably have to tweak one of my TM tests to see).
The way it should work is if any cells in the minicolumn are in a predictive state, then only they become active and the other cells in the minicolumn are inhibited. The cells should only go into a predictive state if they have an active distal segment, which means one that has at least ACTIVATION_THRESHOLD active synapses with a permanence above CONNECTED_PERMANENCE.
I believe the “best matching” logic is only used for selecting a cell for learning when no cells in the minicolumn were predicted and a burst occurs. It will pick up a cell that has at least LEARNING_THRESHOLD active potential synapses (of any permanence), and if none match then it picks the least used cell as a winner.
Thinking this through some more, stabilization could occur if by random chance, the winning cells from step one are chosen through random tiebreaker as “least used cell” in a later burst. For example in my visualization above, if the bottom cell had been chosen in step three, a loop would have been formed, and no bursting would happen from that point on. The more cells per minicolumn, longer the sequence, or more frequently the same input is used in the sequence, the more opportunities for this random selection to occur. Combine this with a long sequence and the culling logic that @cogmission described, and it might mean stabilization is inevitable given enough cycles.
That’s certainly the right logic, and I really thought its what I was doing but am digging to find the difference. It seems I was wrong about my prior theory, as I changed it from activating all matching cells in each active to only doing so with predictive cells and it actually converged a lot faster while only using 1 cell with 1 segment per column! Now I’m confused lol. Here are the plots showing that:
That’s certainly plausible as well, though it seems odd that it would happen consistently with my TM and not with NuPIC - especially since I’m using all the same parameter values
It took a lot more repetitions (~1750), but the Anomaly Score flat-lined at 0 and the number of active cells per column flat-lined at 20. If I’m correct this means that its not de-facto bursting, as 20 cells are activating in each A-column and predicting 20 cells in each B-column.
I also notice the same basic trend in the precisions (number of active cells per column) as shown in my original precision plot, though over a longer time span: