This is the first of a series of tangential theories based on HTM to explore what I believe to be capabilities that could help in simulating parts of the sensory motor system. These may have no basis in reality, and may ultimately have no bearing on that system, but could still be useful for other machine learning problems. The purpose of these threads will be to collaborate in exploring different problems in the hope of distilling useful information.
This first theory involves tweaking elements of HTM so that it can be used to learn and recognize a collection of features in a system where order doesn’t matter. This would be useful in a system where there is some finite number of features, and the order in which they are input can be random. It assumes that the order the features are input doesn’t matter – what matters is the overall collection of features.
In the below explanation of the theory, I use examples touching features of a physical object with a finger. Touch is not a necessary element of this theory, but is helpful in explaining and exploring the theory (and is how I originally thought about it). I decided to explore touch rather than vision because it’s relatively easier for me to think about. Initially, I am also just focusing on sensing differences of pressure. Obviously there is a lot more that can be detected through touch, like temperature, softness, stickiness, etc, but starting with pressure for simplicity.
One thought I had is that objects can be learned and recognized without involving the motor control system. For example if I close my eyes and hold out my finger while someone moves an object against it randomly, I can just as easily recognize a pen, coffee cup, etc as if I were moving my finger to explore the object. I can also learn new objects this way. The important thing to note about this scenario is that I have no way of knowing what order the inputs will be coming, but I can still recognize and learn objects nearly as well as if I were controlling the input through my own motor commands. My thought was to see if I could take this simpler case even a step further to design a system for recognizing an object without requiring depictions of “object space” or “sensor space” at all.
The first idea I had was it might be possible to use semantic meaning of SDR bits to avoid the need for transforming and translating between coordinate spaces. The idea would be that similar sensory inputs should have similar semantic encoding, regardless of the orientation. Imagine a square pressure sensor at the end of your finger. You can detect an edge from many different orientations. Regardless of the orientation, the same edge should always have virtually the same semantic encoding:



Another example of three inputs that should have virtually the same semantic encoding (maybe this could be something like a gap between a point and an edge):



And one more example (side of something long like a pen):



The idea is that an object consists of some collection of semantically dissimilar features. As such, the object can be depicted as a union of those features. So for example, the above three features might be encoded as (using dense SDRs here for explanation purposes):
 =
= 
 =
= 
 =
= 
By touching the object in various orientations, I can learn a union of these three features, which would be something like:

From the above, you can see that learning an object doesn’t require any particular order. This is where the theory starts to diverge from the typical sequence learning. In sequence learning, the difference between ABC and CBA matters, but in this theory, when learning an object both are the same.
So to move away from a system where the order of input matters, to a system where the order doesn’t matter, but instead the unique features are what matters, a few tweaks have to be made (this is where we start to diverge from HTM)
The first thing we need to do is move away from thinking in terms of discrete time (T-1, T, T+1, T+2, etc) and instead have cells learn within some range of time (which I will refer to as the “learning period” for lack of a better term). Enforcement of synapses should not be limited to only between cells that are currently active and cells which were active at T-1. Synapses should be enforced between any cells that were active during the learning period.
Next, the order of activation does not matter. Synapses with cells that become active after a particular cell was active during the learning period should be reinforced as well as synapses with cells that were active before the cell was active. From a sequence perspective, that would be like learning ABC ABC ABC ABC… At this step in sequence learning, C would enforce its synapses with B. In the new system, A and B would also enforce their synapses with C. In other words, a future input of B should put both A and C into the predictive state, not just C.
What this means is that inputting one feature of an object should result in the cells which represent all other features of that object going to the predictive state. In other words, any of the features of the object might be sensed next, in no particular order. Therefore the prediction should be all other features of the object.
Obviously this is a very rough theory, and may have no basis in reality, so looking for folks to poke holes in it as a way of hopefully distilling out something useful. I’ll start the hole-poking myself by pointing out one of the main problems with this theory, which is the concept of the “learning period”. As written, it would require learning one object at a time, and waiting some time between objects for the "learning period’ to end. If I were to start touching a second object too quickly, it’s features become encoded along with the first object. This becomes particularly a problem if you try to extend this theory to vision, where jumping quickly between objects is the norm and not the exception.
Another problem is when a feature is shared between multiple objects, and that feature is input. Initially, the features of all objects which share that feature would be predicted (which should be expected), but I haven’t thought of how sensing other features would “narrow down” the prediction to one object. I am tackling this problem first before I go back to the “learning period” problem.
I’m also developing a simple proof-of-concept app to try and see how well the theory holds up in practice, so I’ll post a link to that when it is complete.
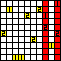
 B:
B: 
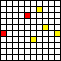 E:
E: 

 )
)