An interesting point that I recently discovered I had misinterpreted in my HTM test implementation compared to the NuPIC implementation is that whenever a column becomes active which has more than one cell in the predictive state, all of those predictive cells should become winners. I am curious about the thoughts behind this, and what disadvantages one might expected by activating only the cell which best matches the previous state (i.e. the cell with the highest number of distal synapses active). I expect part of the answer is simply that NuPIC’s implementation best matches biological systems, but curious if there are any additional insights about this particular point. The behavior will obviously be different when you get to increasing/ decreasing permanence values – not sure what the net effect of that might be.
I can’t provide you with an explanation of the benefits of this, but I can point you to some discussions about this particular feature. The ability to make multiple simultaneous predictions is frequently touted in the HTM literature:
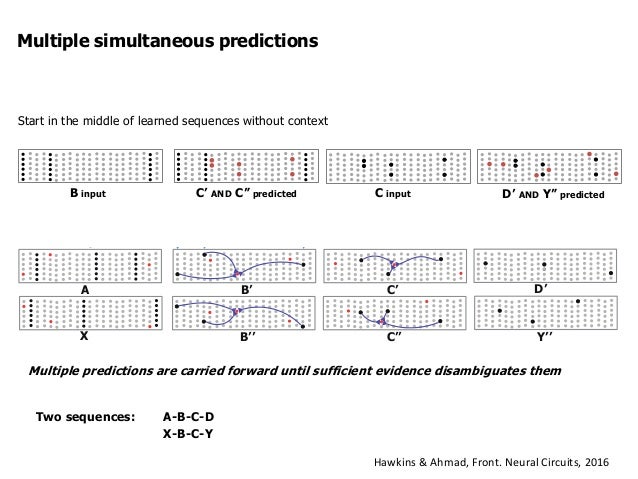
…which comes from slide #13 here
…just a small, hopefully helpful comment.
From Jeff & Subutai’s white paper, “Why Neurons Have Thousands of Synapses, A Theory of Sequence Memory in Neocortex”
More references… (search for Multiple Simultaneous Predictions)
Page 4
Most significant reference in the document… (Page 5)
Paragraph that begins… “Often the network will make multiple…”
Yep, makes perfect sense. The reasoning is the same as for the concept of bursting – predictions narrow down as you get more evidence about which sequence you are in. I am having a problem in my implementation with things being forgotten, and was thinking it might be related to this. Will see if making this change helps any.
On that subject, I was testing those cases in my implementation (which is pretty similar to the java version, also got similar results there), and looks like PredictedSegmentDecrement need to be non zero for that to work.
I tried sequences(with resets between them) such as, 1347, 2346, which worked perfect, then I introduced 1236 and it broke.

now with 1236, the prediction is a bit wrong because it tries to predict it 4 after 3 (but there is no such path 1234 the closest is from 2346), it looks like it does not burst because it can successfully predict the next column, so it does not use other cells in the same column.

So I tried to force it to burst and added a start state input, which made things much better, even perfect.
It can recognize the paths, and show multiple possible predictions.

{kind=link}
Is there something wrong with my settings?
how can I make it predict better without the start state hack?
I skipped SpatialPooler, so only an encoder and TM, maybe it will be better with the SP?
MaxNewSynapseCount = 6;
InitialPermanence = 0.2f;
ConnectedPermanence = 0.8f;
MaxSynapsesPerSegment = 255;
ActivationThreshold = 1;
MinThreshold = 1;
PredictedSegmentDecrement = 0.01f;
PermanenceIncrement = 0.10f;
PermanenceDecrement = 0.10f;
I think that is expected behavior (but someone else correct me if I am wrong).
When you train “2346”, the “2” column always starts out as bursting (because of the reset), and predicts “3 after 2”, which predicts “4 after 3 after 2”. When you then introduce “1236” after a reset, the one column bursts. It predicts the “3” column (because of previous training on “1347”), but you input “2”. That causes the “2” column to burst.
This is now in exactly the same state as when you were training “2346” after a reset. The bursting “2” predicts the same “3 after 2” cell, which subsequently predicts “4 after 3 after 2”. Since the next input is a “6” instead of the predicted “4 after 3 after 2”, the “6” column bursts. A cell in this column grows a distal segment connecting it to the “3 after 2” cell in the previous step.
Thus when you input the next iteration over “123…” it isn’t possible for the system to know whether “4” or “6” will be next (both have distal connections to the active cell).
The connected cells end up looking something like this:

As you can see, there is one cell in the “3” column which has ended up being part of two different sequences. Thus when this cell becomes active, it predicts the next step for both of the sequences. I imagine if you train on one of the two sequences long enough, the permanence values for the other will cause it to stop being predicted, and then retraining that other sequence might pick a different cell in the “3” column, allowing the two sequences to be differentiated. You have to watch that reset though, because it means you are always starting with a bursting column which might result in the same situation as above (where one cell ends up becoming part of two different sequences).
–EDIT– To summarize this more simply… if the first two numbers of one of your sequence are the same two numbers that are part of another of your sequences, and you do a reset at the start of each sequence during training, you will end up seeing this behavior. This isn’t the only way to cause this behavior (in fact your example is a slight variation of this), but it is a simple example for visualizing what is happening.
I am trying to find a way around a very similar problem for the last couple of days. Initially I was doing as Numenta and marking all previously predictive and currently active cells as winner cells. It is important to point out that I am running a non reset implementation. Unfortunately, when you do not reset the sequence once in a while these multiple winner cells per column build up and after some time, the most of the cells in a column becomes predictive rather than 1 or 2. In the end, almost all the the cells of a column becomes winner cells and this behavior quickly spreads on to the whole layer. So I am currently experimenting with choosing only one winner cell inside a column even if there were multiple to kind of sparsity the predictive cells of a column. I am using this cellular activation as input to some other layer so cellular sparsity is an important property for me to preserve.
So far, It does not seem to solve the problem but we’ll see.
I am seeing the same effect in my test implementation as well. The problem is that multiple active cells per column is very similar to bursting, and has a similar effect to what Vovchik described for certain input sequence, where subsequent cells wind up being encoded in multiple sequences (thus accumulating multiple predictions, which in turn can result in multiple active cells in the next columns for certain input sequences, and so-on). The system almost needs to look back more than one time step when it is adjusting connections, so that it can recognize when one cell winds up being part of two similar sequences, so it can correct the issue. Before I go that route, though, think I will play around with NuPIC to see how it handles these scenarios, or if it has the same behavior.
@Paul_Lamb
Thank you for the detailed explanation, looks like you are right.
but this is my concern, I think that the prediction should be better.
I will experiment with some ideas and see how it goes, I hope to find something useful.