tdlr
Given only a map of (nd) point-to-point conversions, and assuming a non-linear transformation, how do I infer the conversion point of a new point?
intro
I know this probably isn’t the best forum to discuss a math question like the one I have but my question, I believe, touches on the foundations of intelligence.
Intelligence is a process whereby a transformation of data from one space to another is learned. The fundamentals of how to do that are what I’d like to discuss and what I’d like to learn more about.
Also, keep in mind I have no background in math. I don’t speak it. This will be quickly apparent, I have to conceptualize everything with images. Talk to me like you would a highschooler… or small child.
problem
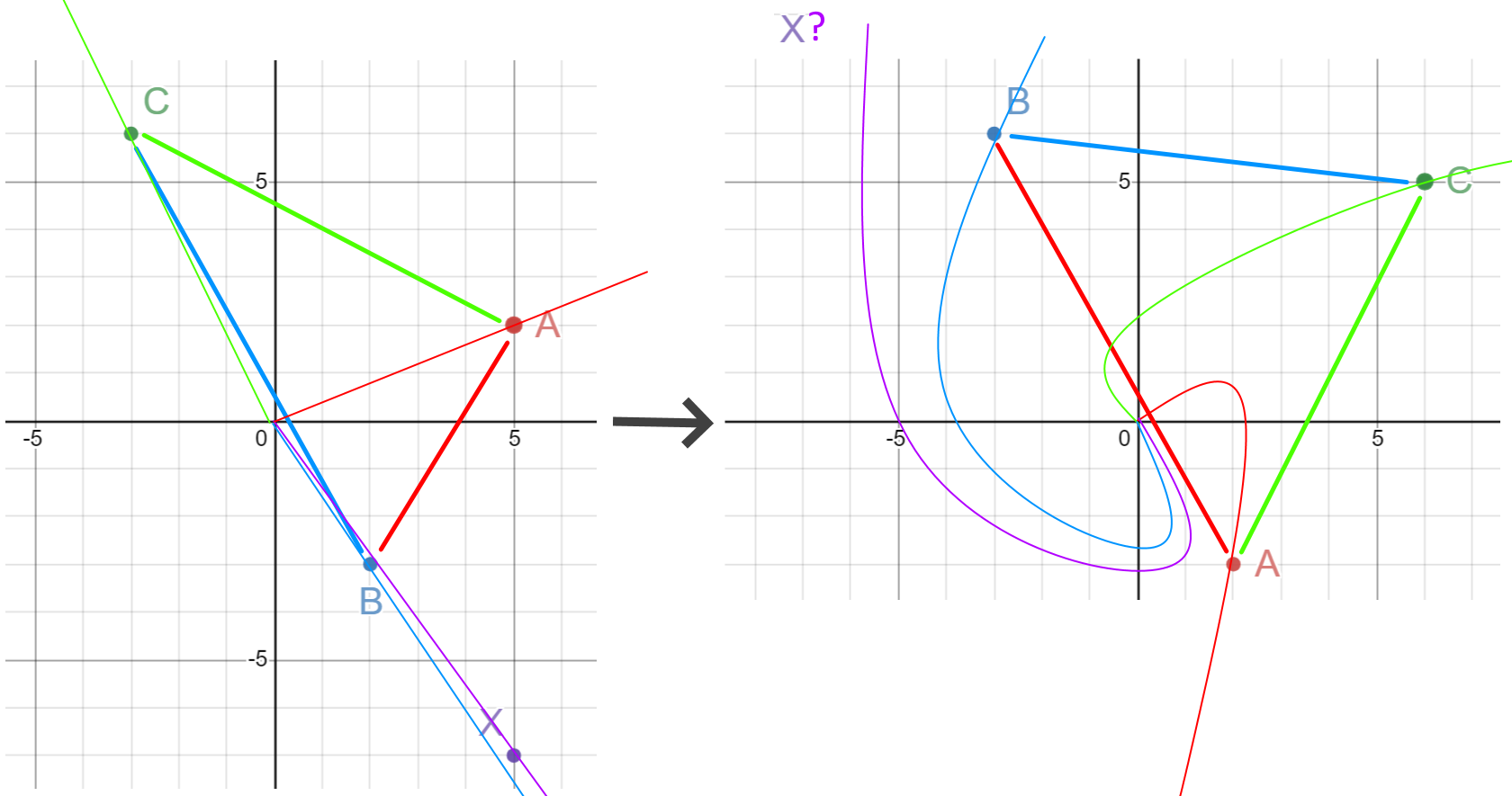
Imagine I have some data points A, B, C, X on a 2d graph like this:

And each of the points (except X) gets transformed to a new set of points like so:
(5, 2) -> (2, -3)
(2, -3) -> (-3, 6)
(-3, 6) -> (6, 5)
(5, -7) -> (?, ?)
To visualize the transformation, it kind of rotates a bit and stretches out a little:

So it goes from this to this:

The question is, where should X be placed in this new space?
There are actually at least a couple of answers to this question given various assumptions, I think. Firstly, you could assume a linear transformation, in my head that looks something like this (don’t know how to do the computation for this, if you do please let me know, but I can ballpark it using reasoning by analogy):

Ok, but I actually think the linear assumption is insufficient. What we really want is to assume a non-linear transformation.
Why?
Because non-linear transformations allow you to describe any transformation. Say we had thousands of points on this graph, not just 3. They might bend the space in all kinds of different ways on local scales. So as I’m trying to understand this, I take the most generalized non-linear transformation as my goal.
Then the question becomes, are there multiple ways to come up with a non-linear transformation from one set of points to another. Well, since I don’t know anything about math, I don’t know, but I have a hunch that the answer is yes.
My first intuition is to consider the origin. Don’t we have to consider where we place the origin?
If we leave the origin where it is the transformation over the whole graph implied by the data is one thing, but if we first move the origin to the center of the cluster of points (except for X) then infer the transformation, it is different. It feels to me like it would be more ‘simplified.’
origin remains at origin
origin at center of cluster (black lines)

Perhaps, in either case, the point-conversion (where they end up relative to each other) is the same so it doesn’t really matter. I don’t know if moving the origin to the center of the cluster before inference produces a different prediction of where X would be in the post-transformation-space (I assume it would), but it’s probably a good idea, just to reduce the complexity of the transformation. (I would assume).
In fact, since we know the distribution of points in the post-transformation-space we might as well take the center of that, take the center of the cluster of the input space and put the origin at the middle of the two points, then do the nonlinear inference to get the right place for our missing X point. But that’s just a tangential thought.
Question:
So the question really is: given only a map of point-to-point conversions, and assuming a non-linear transformation, how do I infer the conversion point of a new point? (in other words, solve for X, where should X go in the post-transformation-space)?
When I ask, “how do I infer…” I really mean how do I compute, since all I speak is code, not math.
afterthought
Perhaps assuming a linear transformation is fine, and much more efficient, so if that’s much easier great, but it just feels like I need a non-linear transformation because I want to describe the transformation exactly. That is I want to know the boundary exactly. Feel free to give me feedback on that.
Anyway, thanks for your attention, I am trying to write a function that will do this and I would appreciate any help you can give me!
def predict(input_coordinates, result_coordinates, point):
'''
given a set of input coordinates and their resulting
coordinates post-transformation, and given an additional
input coordinate return the location (coordinate) in the
post-transformation space that corresponds to the most
logical non-linear transformation of that space for that
additional point. "predict where this point ends up"
'''
Thank you!
Edit: I just wanted to say, it seems obvious to me now that a non-linear transformation involving 3 points on a 2d graph is equivalent to a linear transformation involving 3 points on a 2d graph. More points, could warp the space in different ways unable to be expressed by a linear transformation but restrict it to 3 points, and the two models should be equivalent, and therefore make equivalent predictions about an additional point.

 and someone might want to see this someday.
and someone might want to see this someday.