Supplementary material:
For example, if cell G(1,1) is active for a location on an object, a movement one step to the right will cause G(2,1) to become active. Since the cells tile space, an additional movement one step to the right will cause G(0,1) to become active.
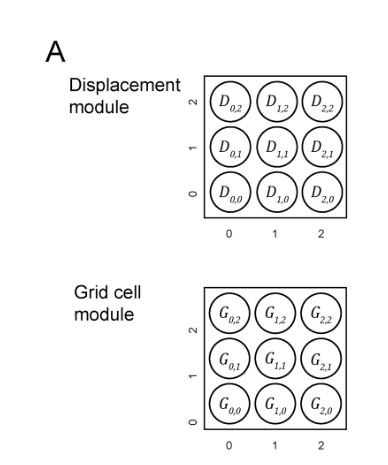
In the Grid cell module in the Figure A when the cell G(1,1) is active a single step movement can be 1 step to the “left”, “right”, “up”, “down”, “left-up”, “left-down”, “right-up”, “right-down” (diagonally) or “none” (same place but 1 step through time). All these count for 9 displacements of 1 step.

Figure B shows that independent of which cell performs the 1 step to the right movement D(1,0) will represent the displacement.
Questions:
- Can there be displacement cells representing 2,3,n steps?
- X
- X
Adding to the answer:
This formula in the supplementary material for the 3x3 grid cell lattice example:
G(x1,y1) → G(x2,y2): D((x2-x1) mod 3, (y2-y1) mod 3)
Seems to work for any NxN grid cell lattice and can represent 2,3,n steps.
G(x1,y1) → G(x2,y2): D((x2-x1) mod N, (y2-y1) mod N)
In a 3x3 grid cell module the ambiguity of “4 steps to the right” displacement landing in the same location as the “1 step to the right” displacement is resolved by adding more grid+displacement cell modules. The “4 steps to the right” will be represented by the same displacement cell D(1,0) that represents the “1 step to the right” due to how space is tiled:
N=3: “1 step to the right” => x2 = x1 + 1, y2 = y1
D((x1 + 1 - x1) mod 3, (y1 - y1) mod N)
D(1 mod 3, 0 mod 3)
D(1, 0)
N=3: “4 steps to the right” => x2 = x1 + 4, y2 = y1
D((x1 + 4 - x1) mod 3, (y1 - y1) mod N)
D(4 mod 3, 0 mod 3)
D(1, 0)

