Hello, I am interested in the application of the Nupic. Now , i find some parameters in rec_center_hourly_model_params.py, but i dont understand the meaning.The parameters are listed below:
‘modelParams’: { ‘anomalyParams’: { u’anomalyCacheRecords’: None,
u’autoDetectThreshold’: None,
u’autoDetectWaitRecords’: None},
I dont understant the meaning about the anomalyCacheRecords, autoDetectThreshold,autoDetectWaitRecords. What meanings are these parameters? How are these parameters used in the model? what functions used these parameters?
Hi @immortalluo, welcome to the forums! I’m not the most experienced here, but I’ll have a shot at helping you - hopefully I don’t lead you astray
The particular parameters you are looking at relate to what constitutes an anomaly in a stream of data. HTM makes predictions based on sequences, but whether or not an incorrect prediction should be interpreted as an anomaly is open to some tuning.
In particular, page 3 shows a box: “Prediction Anomaly Detection Classification” which takes the output from the HTM learning algorithms.
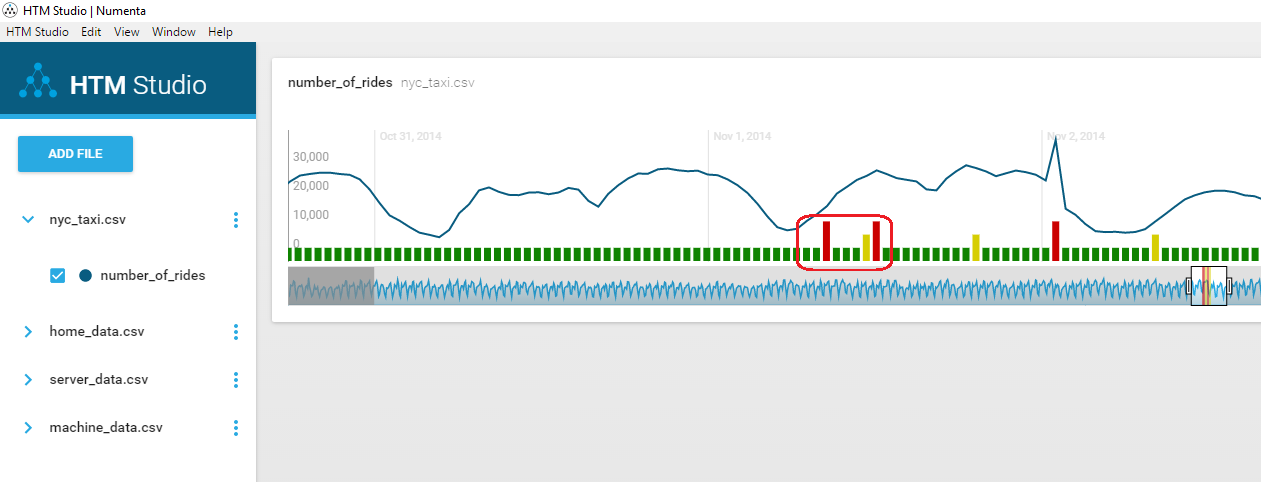
You can see this relationship nicely in HTM Studio - there is a stream of data that HTM is learning to predict the next value of, then separately there’s a classifier which determines the level of anomaly based on the success of the prediction: