Hi everyone,
We’re recently using nupic as an anomaly detector in a complex periods data envolving daily period/weekly period/monthly period. Thus, we’re getting data from seven different nodes into the same cluster, the load are well balanced so each node is processing the same number of requests (the metric that we’re analizing is our web site load) and all of them have the same behaviour.
Some more context:
1.- Our data are five minutes aggregated with two months deep. We’re processing data split by nodes in different and isolated streams.

2.- That’s the best model we found. (Unexpectedly, without timeOfWeek and weekend enconding)
{
"inferenceArgs": {
"predictionSteps": [1],
"predictedField": "c1",
"inputPredictedField": "auto"
},
"aggregationInfo": {
"days": 0,
"fields": [],
"hours": 0,
"microseconds": 0,
"milliseconds": 0,
"minutes": 0,
"months": 0,
"seconds": 0,
"weeks": 0,
"years": 0
},
"model": "CLA",
"modelParams": {
"anomalyParams": {
"anomalyCacheRecords": null,
"autoDetectThreshold": null,
"autoDetectWaitRecords": 5030
},
"clEnable": true,
"clParams": {
"alpha": 0.035828933612157998,
"clVerbosity": 0,
"regionName": "CLAClassifierRegion",
"steps": "1"
},
"inferenceType": "TemporalMultiStep",
"sensorParams": {
"encoders": {
"timestamp_timeOfDay": {
"fieldname": "timestamp",
"name": "timestamp_timeOfDay",
"timeOfDay": [
21,
9.5
],
"type": "DateEncoder"
},
"timestamp_dayOfWeek": null,
"timestamp_weekend": null,
"value": {
"name": "value",
"fieldname": "value",
"numBuckets": 150,
"seed": 42,
"type": "RandomDistributedScalarEncoder"
}
},
"sensorAutoReset": null,
"verbosity": 0
},
"spEnable": true,
"spParams": {
"potentialPct": 0.8,
"columnCount": 2048,
"globalInhibition": 1,
"inputWidth": 0,
"maxBoost": 1.0,
"numActiveColumnsPerInhArea": 40,
"seed": 1956,
"spVerbosity": 0,
"spatialImp": "cpp",
"synPermActiveInc": 0.003,
"synPermConnected": 0.2,
"synPermInactiveDec": 0.0005
},
"tpEnable": true,
"tpParams": {
"activationThreshold": 13,
"cellsPerColumn": 32,
"columnCount": 2048,
"globalDecay": 0.0,
"initialPerm": 0.21,
"inputWidth": 2048,
"maxAge": 0,
"maxSegmentsPerCell": 128,
"maxSynapsesPerSegment": 32,
"minThreshold": 10,
"newSynapseCount": 20,
"outputType": "normal",
"pamLength": 3,
"permanenceDec": 0.1,
"permanenceInc": 0.1,
"seed": 1960,
"temporalImp": "cpp",
"verbosity": 0
},
"trainSPNetOnlyIfRequested": false
},
"predictAheadTime": null,
"version": 1
}
So, we hope get the same results (more or less) for all the nodes.
But…
1.- We’re getting a lot of diferences (anomalyLikelihood) between similar series. In peaks, not all series are reporting a high anomalyLikeHood ( > 0.80)
2.- Very clear anomalies are not detected (Detected anomalies are marked with a red circle)
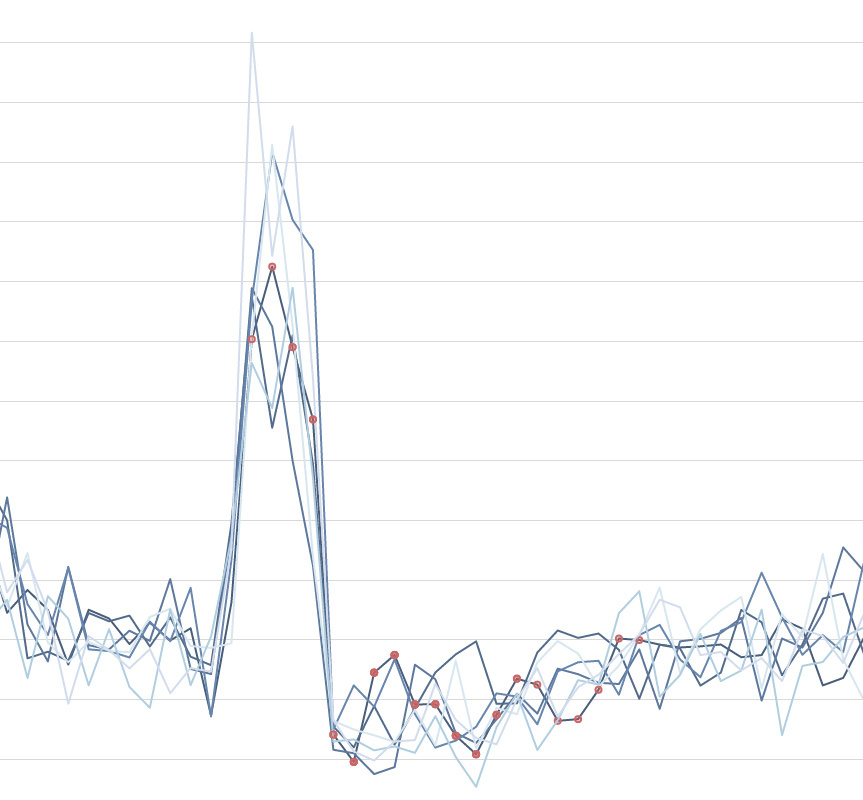
3.- Strongs falls in the metrics aren’t detected

We’re a little lost. So any sugestion will be appreciated.
Regards


