The idea is to learn a collection of named sequences, and then when you input a fragment of a curve name and predict which one it belongs to. The hypothesis is that the brain is doing something similar. For example, say you start spelling out a word: ‘f’, ‘fr’, ‘fro’, … With just an f it could be any word with an f in it. Then ‘fr’ narrows it down a little. Then ‘fro’ narrows it down further. Eg, to ‘frog’, or ‘from’ or etc. But it applies to floats and integers too. Say you start with 3. This could belong to almost any sequence/curve right? But what if the next symbol is ‘.’. And the next is 1. Suddenly you would predict Pi: 3.141592… Now what about floats? An example I like is playing football. Someone kicks the ball a long way, and your brain is trying to predict where it will fall so you can catch it. The hypothesis is that you have seen the football fall so many times that you have a big collection of stored sequences of falling football positions. As it falls, the number of matching predictions shrinks, until you know enough to get in the right position and catch the thing. It certainly seems more plausible the brain is doing this than solving some physics equation.
Now on to some worked examples:
Input a decimal point, and we get Pi and e:
$ ./seq2name.py '.' float_sequence: input sequence: ['.'] name similarity prediction ---- ---------- ---------- Pi 100 . 1 4 1 5 9 2 6 5 3 5 8 9 7 9 3 2 3 8 4 e 100 . 7 1 8 2 8 1 8 2 8 4
Input Fibonacci but with a couple of minor errors:
$ ./seq2name.py 1 1 2 3 5 7 13 21 36 float_sequence: input sequence: [1, 1, 2, 3, 5, 7, 13, 21, 36] name similarity prediction ---- ---------- ---------- Fibonacci 44.271 1 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 counting 6.541 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 Pi 5.237 2 6 5 3 5 8 9 7 9 3 2 3 8 4 6 2 6 4 3 3 counting 4.259 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Pi 2.112 2 6 4 3 3 8 3 2 7 9 5 e 1.689 1 8 2 8 1 8 2 8 4 factorial 1.562 1 1 2 6 24 120 720 5040 40320 362880 3628800 Pi 0.872 3 2 3 8 4 6 2 6 4 3 3 8 3 2 7 9 5 Pi 0.778 1 5 9 2 6 5 3 5 8 9 7 9 3 2 3 8 4 6 2 6 Fibonacci 0.488 1 2 3 5 8 13 21 34 55 89 144 233 377 610 987 Pi 0.455 1 4 1 5 9 2 6 5 3 5 8 9 7 9 3 2 3 8 4 6 factorial 0.423 1 2 6 24 120 720 5040 40320 362880 3628800 Pi 0.42 2 3 8 4 6 2 6 4 3 3 8 3 2 7 9 5
Learn two simple sentences: “boys eat many cakes” and “girls eat many pies”, then input a sentence fragment:
$ ./seq2name.py eat float_sequence: input sequence: ['eat'] name similarity prediction ---- ---------- ---------- boy sentence 100.0 eat many cakes girl sentence 100.0 eat many pies boy sentence 16.667 cakes alphabet 16.667 a b c d e f g h i j k l m n o p q r s t alphabet 16.667 e f g h i j k l m n o p q r s t u v w x alphabet 16.667 t u v w x y z boy sentence 11.111 many cakes girl sentence 11.111 many pies girl sentence 11.111 pies
Now a sentence fragment with a typo:
$ ./seq2name.py eats mnay float_sequence: input sequence: ['eats', 'mnay'] name similarity prediction ---- ---------- ---------- boy sentence 55.556 eat many cakes girl sentence 55.556 eat many pies boy sentence 11.111 boys eat many cakes boy sentence 9.722 many cakes girl sentence 9.722 girls eat many pies girl sentence 5.556 many pies alphabet 5.556 a b c d e f g h i j k l m n o p q r s t alphabet 5.556 e f g h i j k l m n o p q r s t u v w x alphabet 5.556 s t u v w x y z alphabet 5.556 t u v w x y z
Now on to pretty pictures:
Here are the simple curves we have learnt (trivial to add more to our collection):

Now input a short curve:
$ ./seq2name.py 0 0 2 2 2 2 float_sequence: input sequence: [0, 0, 2, 2, 2, 2] name similarity prediction ---- ---------- ---------- square 96.875 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 triangle 8.704 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 0.36 0.28 0.2 0.12 0.04 sin 8.46 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 sin 8.435 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 sin 8.366 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 sin 8.271 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 -0.058 sin 8.221 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 triangle 7.912 0.56 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 0.36 0.28 0.2 0.12 0.04 sin 7.534 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 triangle 7.252 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 0.36 0.28 0.2 0.12 0.04 sin 6.761 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 -0.058 -0.158 sin 6.366 0.0 0.1 0.199 0.296 0.389 0.479 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 zero 6.25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 zero 6.25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 zero 6.25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 zero 6.25 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Producing these predictions:

Now input a longer curve:
$ ./seq2name.py 0 0 2 2 1.5 1.5 1.6 1.7 1.4 1.5 1.1 1.1 1.1 1.3 1.2 1.9 1.7 1.7 1.6 1.5 1.8 float_sequence: input sequence: [0, 0, 2, 2, 1.5, 1.5, 1.6, 1.7, 1.4, 1.5, 1.1, 1.1, 1.1, 1.3, 1.2, 1.9, 1.7, 1.7, 1.6, 1.5, 1.8] name similarity prediction ---- ---------- ---------- square 59.236 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 sin 19.732 0.0 0.1 0.199 0.296 0.389 0.479 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 sin 18.779 0.1 0.199 0.296 0.389 0.479 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 sin 16.873 0.199 0.296 0.389 0.479 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 sin 13.248 0.296 0.389 0.479 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 sin 11.295 0.389 0.479 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 sin 9.429 0.479 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 sin 6.947 0.565 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 triangle 5.421 0.0 0.08 0.16 0.24 0.32 0.4 0.48 0.56 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 sin 5.293 0.644 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 triangle 3.897 0.08 0.16 0.24 0.32 0.4 0.48 0.56 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 sin 3.502 0.717 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 triangle 3.084 0.16 0.24 0.32 0.4 0.48 0.56 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 0.36 sin 2.462 0.783 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 triangle 2.276 0.24 0.32 0.4 0.48 0.56 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 0.36 0.28 sin 1.718 0.841 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 triangle 1.587 0.32 0.4 0.48 0.56 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 0.36 0.28 0.2 sin 1.302 0.891 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 triangle 1.192 0.4 0.48 0.56 0.64 0.72 0.8 0.88 0.96 1.04 0.92 0.84 0.76 0.68 0.6 0.52 0.44 0.36 0.28 0.2 0.12 sin 0.846 0.932 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 sin 0.609 0.964 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 -0.058 sin 0.38 0.985 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 -0.058 -0.158 sin 0.268 0.997 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 -0.058 -0.158 -0.256 sin 0.166 1.0 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 -0.058 -0.158 -0.256 -0.351 sin 0.12 0.992 0.974 0.946 0.909 0.863 0.808 0.746 0.675 0.598 0.516 0.427 0.335 0.239 0.141 0.042 -0.058 -0.158 -0.256 -0.351 -0.443
Producing these predictions:

Now learn some simple paths:

Now input the starting point (1,1):
$ ./seq2name.py '(1,1)' float_sequence: input sequence: [(1, 1)] name similarity prediction ---- ---------- ---------- path a 100.0 (1, 1) (1, 2) (1, 3) (2, 4) (3, 4) (3, 5) (3, 6) (4, 6) (5, 6) (6, 6) (7, 6) path b 100.0 (1, 1) (2, 1) (3, 1) (4, 1) (5, 1) (6, 1) (6, 2) (5, 3) (5, 4) (5, 5) (6, 5) (7, 6) path c 100.0 (1, 1) (1, -1) (0, -0.7) (-2.5, 3.2) (-4, 2.1) (-5, 5) (-7, 3) (-8, 0) path a 8.269 (1, 2) (1, 3) (2, 4) (3, 4) (3, 5) (3, 6) (4, 6) (5, 6) (6, 6) (7, 6) path b 8.269 (2, 1) (3, 1) (4, 1) (5, 1) (6, 1) (6, 2) (5, 3) (5, 4) (5, 5) (6, 5) (7, 6) path c 0.034 (0, -0.7) (-2.5, 3.2) (-4, 2.1) (-5, 5) (-7, 3) (-8, 0) path a 0.031 (1, 3) (2, 4) (3, 4) (3, 5) (3, 6) (4, 6) (5, 6) (6, 6) (7, 6) path b 0.031 (3, 1) (4, 1) (5, 1) (6, 1) (6, 2) (5, 3) (5, 4) (5, 5) (6, 5) (7, 6)
Producing these predictions:

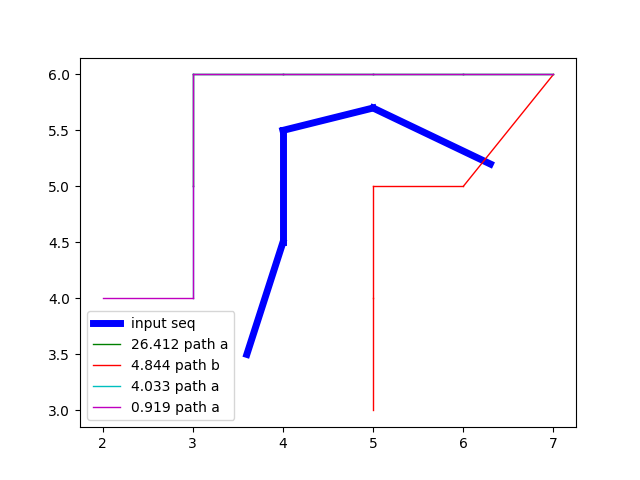
Finally, input a short path:
$ ./seq2name.py '(3.6,3.5)' '(4,4.5)' '(4,5.5)' '(5,5.7)' '(6.3,5.2)' float_sequence: input sequence: [(3.6, 3.5), (4, 4.5), (4, 5.5), (5, 5.7), (6.3, 5.2)] name similarity prediction ---- ---------- ---------- path a 26.412 (3, 5) (3, 6) (4, 6) (5, 6) (6, 6) (7, 6) path b 4.844 (5, 3) (5, 4) (5, 5) (6, 5) (7, 6) path a 4.033 (3, 4) (3, 5) (3, 6) (4, 6) (5, 6) (6, 6) (7, 6) path a 0.919 (2, 4) (3, 4) (3, 5) (3, 6) (4, 6) (5, 6) (6, 6) (7, 6)
Producing these predictions:
Code here.
