If I saw split-second flash image of an object I would recognize it. It would be far too fast for saccades to scan. However, to recognize an object by touch my skin will need to scan over the surface of the object - which requires movement, which happens in time. If I were to recognize an object by sound my ears will need the vibrations over time. The only reason time is involved with temporal sensors is because a spacial ‘picture’ needs to be built up over time. A bit like a computer scanner. As it scans across the page in time it gradually builds a spatial picture. Like the sense of touch, your skins scans the surface of the object forming a gradual spatial ‘picture’. However, if time is not needed it will be spatial by default (like vision and smell and taste… and positional touch).
Given a stream of 1 second data from all senses (disabling visual saccades) they will all have spatial input/‘picture’ (set of simultaneous action potentials) similar to that of a single frame of an image. The picture from the touch of a stone may look like a series of bumps and dots. The picture from auditory of a stone hitting the floor may look like a sudden attack/decay waveform.
Forgive my naivety, but could an encoder be created to collapse temporal data into spacial data? If so would it have practical use?
In this paper the authors talked about how spatial information can be encoded as temporal streams, and how information can be decoded using various paradigms.
I think @ycui is leading in the right direction above. The temporal dimension allows brains to explore spatial dimensions. Without the temporal dimension, we would have one spatial view of the universe, no dynamism, no discovery, no intelligence. It would never change. It’s a pretty boring existence.
Life has evolved to process spatial information over time and take action upon it. Without time, there is no life (as we know it). HTM is trying to mimic something occurring in living brains, and the brain is entirely based upon temporal processing of life happening in front of its sensors.
Without time, you are just a dumb rock.
So from my standpoint, the temporal / spatial combination of sparse neuron activations in response to the stimulus of life is crucial to HTM.
I’ve been thinking a lot about how to visualize a temporal sequence stored in the TM. It’s a challenging problem to think about. I am trying to visualize a sequence somehow spatially, in a picture or graph or something. But I’m coming to the conclusion that it is impossible to display something inherently temporal in nature in a spatial fashion.
A temporal sequence stored in the TM is very high-dimensional. You can represent one sequence like ABCD in a temporal array of SDRs representing cell activations. But each step in the sequence means very little without showing how they are linked together.
Also each step in the sequence might branch off into other sequences, or merge with them. This is very hard to comprehend.
Hi Matt, I’m not sure the question are quite the same. Now that I have a better grasp of HTM I can probably explain my question better.
Just as spatial pooling encodes SDRs representing space, temporal pooling encodes SDRs representing time. Either way they are still the same thing in theory (in my theory anyway…).
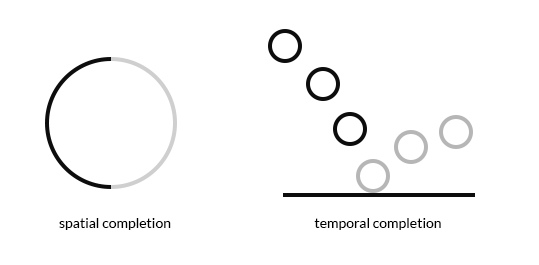
We can think of something spatial as being a ‘snapshot’ of something in time. In the cortex something temporal is also represented as a ‘snapshot’. So a spatial pooling of the ‘snapshot’ of a ball in the air (those dumb circles are meant to represent a ball eventually hitting the floor) is equivalent to the temporal pooling of the ‘snapshot’ of the whole sequence - as if it were a single spatial ‘snapshot’.
This is how we can predict far into the future, when enough spatial cues activate the temporal representation of the whole sequence (completion). Its the same thing as if there is enough spatial cues to activate the whole of a spatial representation (completion).
At the end of it all, I suppose space and time are represented in the same (or similar ways), the only difference is dimensionality. Just a theory.
This is where I disagree with you. Time is more than just the 4th dimension, IMO, it is inherently different from the first three.
The only reason we can complete this temporal pattern on the right:
is because we have learned to do so by observing spatial patterns over time. These patterns are stored between our neurons, and they cannot be extracted without a sample point. You can’t pull a complete sequence out of there within knowing part of the sequence, and even then you won’t just get one sequence, you could get hundreds or thousands.
For example, say you have a set of active columns that represent something spatially. This thing, let’s call it “X”, has no context. But we want to extract sequences from the cells that overlap this pattern. Because X has probably already been seen in many contexts before, when we match for X we’ll get a lot of different cells. We can’t tell which ones belong to which sequences, or even how many sequences are represented.
My point is that a spatiotemporal structure is much more than just the addition of a dimension to the data, especially when it comes to how it is stored and extracted in the brain.
Aha, I had a feeling you were going to bring up temporal memory
If we were to map each function: (spatial pooling - 3d), (temporal pooling - 4d), (temporal memory - 5d). Because there are potentially infinite variations of a sequence there is the 5th dimension that temporal memory encodes.
If you saw a few frames of a ball falling to the floor you would invariably be able to complete the sequence. These hundreds or thousands of sequences is what makes up invariance (like the top set of images). However, one of these invariant sequences are going to win-out over the others due to temporal context and/or feedback. The winning sequence is the specific sequence (due to distal and/or apical excitation).
As I believe spatial and temporal pooling encode ‘their own dimensions’ in similar ways, temporal memory doesn’t due to lateral connections.
edit: I probably didn’t explain that well. Maybe I can improve it tomorrow.
I think this is valid from my own research. Let’s look at a 3x3 monochromatic image of pixel values between 0.0f and 1.0f:
0.0f 0.5f 0.0f
0.5f 1.0f 0.5f
0.0f 0.5f 0.0f
This monochromatic image is the “input space” of the spatial pooler. Spatial pooling encodes this input space at a single time step into a sparse set of neuron activations:
1000
Taking this further, we can label this specific configuration neuron activations as “spatial encoding 0” and put it into a bank, or memory of spatial encodings:
se0: 1000
se1: 0100
se2: 0010
…etc.
I included two new spatial encodings into the bank for the next example. Say after a while we see this sequence of spatial encodings:
se0 → se1 → se2
This sequence is the “input space” of the temporal pooler. Temporal pooling encodes a this input space into… (I’m actually not sure for HTM). However, we can label this specific sequence as “temporal encoding 0” and put it into a bank, or memory of temporal encodings:
te0: se0 se1 se2
…etc
Fundamentally the function of the spatial pooler and temporal pooler are the same: They take an input space and encode it into something else like a label (spatial encoding 0, 1, 2… and temporal encoding 0, 1, 2…). The difference between these two functions is the input space they observe.