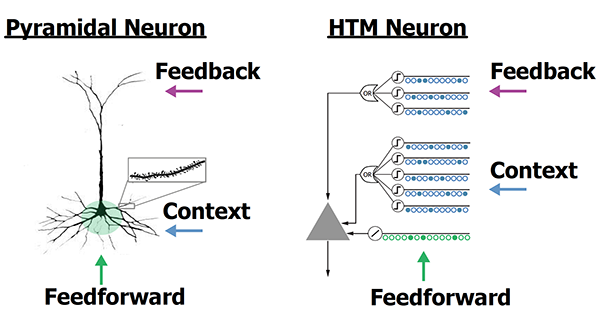
I disagree on this point. The cells are the lowest processing structures, not the minicolumns. Without the cells, you are limited to spatial pooling, and cannot produce high-order memory and anomaly detection. Additionally, experiments which deal with Apical feedback operate on the level of individual cells, not the minicolumns.
For reference, this is the structure of a cell in HTM:
The (HTM) diagram shows what I take to be SDR bit patterns as inputs. How many? The example would appear to show 9, and if each is 2000 bits, that’s 18000 bits of input. How many cells are needed to generate that?
The OR gate is shown as a separate operator. Is that not part of the (HTM) cell?
The triangle is presumably the HTM algorithm, and generates a single bit of output (the cell fires or it does not). Is that algorithm spelled out? Is it fixed, or is there variability between cells?
Given an SDR of 2000 bits, it would take 2000 cells like this one to generate a single SDR, yes?
So, does the minimum processing unit capable of generating an SDR correspond to a column?
Is that a serious question, or are you making a point that I should provide more detail? If the former… well, a typical configuration sets an upper boundary at 255 synapses per segment, and 255 segments per cell. But that might be a little busy to draw…
The whole diagram depicts the concept of an HTM cell.
Again, I assume you are trying to make a point that I should post more detail. I don’t think that is necessary here – folks can refer to Numenta’s papers and BAMI among many other resources here on the forum.
Assuming by “column” you mean minicolumn, then no, a collection of cells in different minicolumns produce an SDR. A single minicolumn (when not bursting) is only capable of generating one bit of an SDR. If you are referring to a cortical column, then sure - it takes a network of cells to construct an SDR. Of course you also changed the subject here – I was referring to the “lowest processing structure” in the HTM algorithm, not the “minimal processing unit capable of generating an SDR”.
Relating this back to the original subject:
Clearly, by “column” Cairo was talking about HTM minicolumns here – specifically the SP algorithm which has an optimization whereby multiple cells sharing a receptive field are modeled as all sharing a single proximal segment (as if the minicolumn itself were a neuron in the case of feedforward processing). He was not talking about cortical columns. I don’t think anyone would assert that a cortical column in HTM is equivalent to a neuron in other algorithms.
BTW, for Cairo’s benefit, that particular optimization applies only to feedforward processing in the SP algorithm. There is more to HTM than just the SP algorithm, though, so from a broader perspective I do not feel it is accurate to think of single HTM minicolumns in general as being equivalent to single neurons in other algorithms.
Actually all I’m trying to do here is to get a clear mental picture of basic HTM, in consistent and widely accepted terminology. This one thread and its parent have about 6 different kinds of column and talks about a ‘cell’. To me a cell is a single neurone (of any kind) and equating it to a ‘column’ or a ‘processing structure’ makes no sense.
I took ‘processing structure’ to mean column, as per BAMI:
Column: An HTM region is organized in columns of cells. The SP operates at the column-level, where a column of a cells function as a single computational unit.
Mini-column: See “Column
I read that to say (a) there is only one kind of column in HTM and (b) the column is the (only) computational unit (structure).
My questions were trying to fix the scale: were we talking about columns of a few neurones or thousands? If the key algorithms in HTM use the SDR then surely the key processing unit is one that deals in SDRs? How many neurones/columns does it take to produce one SDR?
The diagram you quoted is in BAMI and makes perfect sense, but I can’t find any such diagram for columns or any higher level structures. They would really help.
I definitely feel your pain. I have seen many conversations using the term “column” when talking about both minicolumns and cortical columns, despite them being two very different concepts. IMO, the HTM community should abandon use of the word “column” by itself, and always say either minicolumn or cortical column, depending on which concept they are discussing. Of course the difficulty with that is a lot of historic documentation exists, so anyone doing a deep dive into HTM is going to run into this.
Going back to BAMI, the column they are referring to there is the minicolumn. In most applications, this is a collection of 32 neurons (configurable) which all share a receptive field and are able to inhibit each other if they fire before the others.
In the case of minicolumns, a few, not thousands.
I think that this is slightly the wrong question. A single cell can deal with SDRs, but it obviously takes thousands of cells to represent an SDR. If the question were re-phrased to something like “what is the smallest, repeatable unit in the neocortex”, then it would be easy to say the cortical column, not the minicolumn.
That said, I took “lowest processing structure of HTM” to mean the level where learning occurs in the system. From that perspective, I think the lowest processing structure is the neuron (especially since Cairo was making a comparison with neurons in other algorithms). One could even argue that the lowest structure is the segment (since that is where the learning and SDR recognition occurs). Ultimately it is probably trying to compare apples to oranges, though – the algorithms are not the same, and such discussions are really only useful insofar as they help to address our misunderstandings of them.
Yes, as long as it is not confused with minicolumn. I’ve mainly seen folks on the forum use “cortical column”, “macrocolumn”, “hypercolumn”, and “region” interchangably for this concept, as well as attempting to coin some new terms like SUI (Single Unit of Intelligence) and CPU (Cortical Processing Unit). I love the creativity of the folks in this community
Hey @david.pfx, have you seen the HTM School videos on YouTube? If not I’d highly recommend this series because of its great dynamic visualizations, showing how the systems works overall.
Here’s my understand of the data structures from largest to smallest:
Macro Columns (each w/some amount of regions like L4/L2/L6)
Mini-Columns (each w/ one proximal dendrite segment - for SP functioning)
Cells (each w/up to some max # of distal dendrite segments - for TM functioning)
Distal dendrite segments (each w/up to some max # of synapses)
Synapses (each w/a permanence value from 0 to 1 - those which exceed activation threshold are active)
Back in 2013 Jeff Hawkins enunciated 6 principles. Two of those were SM and SDR. That’s what got me in.
So if I understand correctly you identify 3 levels in HTM:
Cell, which recognises (a part of) an input SDR in an SDR context and outputs a single bit (of an SDR)
Mini-column, which recognises a sequence (of inputs in a time-varying context) and outputs a sequence of bits (of a sequence of SDRs)
Maxi-column, which recognises a sequence of input SDRs (in a time-varying context) and outputs a recognition SDR (of that sequence).
Input SDRs are the output of an encoder step. Context SDRs are the result of recognising successive parts of a sequence. Sequence memory lies in the set of context SDRs accumulated by the maxi-column in response to past inputs.
Whether I’ve got that right or not, I do think BAMI could benefit from a description of that kind, along with a couple of diagrams.
I’ve watched every video, read every paper (that is about HTM and not neuro-science) and tried all the software. I’m not interested in synapses, dendrites or regions unless those are part of the HTM theory and corresponding software implementation.
As per my other post, it looks like I should be interested in cells, mini-columns and maxi-columns and any specific reading on that subject would be welcome. A diagram would be even better.
I would tweak this a bit. A minicolumn doesn’t recognise a sequence – it only receives feedforward input. So a minicolumn can recognize spatial information from the input space. It is the individual cells within the minicolunn which (in the case of TM) recognize their place in a sequence. Of course I may be splitting hairs by making a distinction between a minicolumn and the cells within that minicolumn.
This is true only in the case of the TM algorithm. In terms of the broader theory, a cortical column does more than just recognize sequences. It is able to recognize objects (the focus of current research) and likely produce output which enables action selection (future research). It most likely also performs feature extraction and association functions. Understanding exactly what a cortical column does is the goal of HTM research.
If you follow Numenta’s approach and call out separate “layers” of a cortical column which perform different functions, then you could say a TM layer “recognises a sequence of input SDRs (in a time-varying context) and outputs a recognition SDR (of that sequence)” as you stated.
BTW, diagrams of a cortical column are in constant flux (and parts are missing) as the theory evolves. There are some diagrams in the Framework paper, as well as on Slideshare (for example, see the Thousand Brains Theory slides). However, I think the best way to keep up to date is to follow Numenta’s research meetings and talks.
The point of my post was for someone to point out my errors, and provide a corrected version. We’re not there yet.
The BAMI summary of terminology does not provide definitions for feedforward or layers. There is nothing in that diagram about cells being able to recognise spatial information, or what that information might be or how it might be encoded, or how a cell might recognise its position in a sequence.
There is always future research, but I just want to know where we are now. What is the current state of HTM theory, what model does it support, what are the algorithms, what can it do.
If the answer is: here it is in 10 pages, go read and understand, that’s great, point me to it. If the answer is: we don’t know yet but we’ve got some interesting ideas, then fine, at least I’ll know where we’re at.
It sounds like you want a simple (10 page?) snapshot that captures the current state of HTM theory and encompasses all terminology with no assumptions of domain knowledge. I don’t think you’ll have any luck finding such a document. You’ll have to do the leg work like the rest of us.
Thanks, @sheiser1 this is not a bad summary of the sequence memory aspect of HTM. I don’t think it is what @david.pfx is looking for, though, for a couple of reasons. Firstly, I think BAMI covers all of this already, and the complaint about BAMI was the lack of explaining all domain terminology (“feedforward” and “layers” as examples). It also doesn’t cover any of the aspects of TBT which are more recent to the theory.
Hopefully this doesn’t come off as a criticism of your post. I’m just pointing out that the sort of documentation that I think is being requested probably doesn’t exist, in part because contributing to HTM theory requires some level of domain knowledge which requires an outsider to work to develop, and in part because while some elements of the theory are stable, others are evolving quickly.
It’s true I don’t think I’ve seen docs describing that, I must’ve gotten it from listening to Numenta people like Jeff & Subutai talk.
I know there is a talk where they do contrast the mechanics of HTM and conventional ANN, but it’s true that terms like “feedforward” and “layers” have totally different meaning in HTM vs ANN.
When I hear “feedforward” in HTM I think of Spatial Pooler activation. The “feedforward” input is ingested by the SP and determines which columns will activate. This is as opposed to the TM deciding which cell(s) in these columns will become predictive, and capable of inhibiting all other cells in their column if that column activates at the next time step. I’m not sure the term for this kind of input though, I don’t think it’s “feedback”.
So rather than thinking in terms of “feed forward/back/whatever” I think of it as activating inputs (used by the SP’s proximal dendrite segments to choose winning columns) and then depolarizing inputs (used by the TM’s distal dendrite segments to make certain cells predictive). The SP’s proximal segments are connected to the encoding, thus saying “here’s what I’m seeing now”, while the TM’s distal segments are connected to other cells within the “region/layer”, thus saying “here’s the sequential context in which I’m seeing it”. Come to think of it I’m not sure the difference between “layer” and “region”, or if they’re interchangeable.
When I hear “layer” in HTM I think of one of these SP+TM modules, which has some activating input and some depolarizing input. The activating (SP) input doesn’t necessarily have to come from a raw data encoder, it could be an output from another layer. It’s just a population for the layer’s SP’s proximal segments to connect to. Likewise the depolarizing ™ input doesn’t necessarily have to come from other cells in that layer. It’s just a population for the region/layer’s TM’s distal segments to connect to.
The largest data structure in HTM (afaik) is the macro column, which is composed of multiple layers. Here’s a repo where different kinds of macro columns are built using the Network API:
Here’s an example of one such macro columns structure:
We can see that L4 is activated by raw data from “Sensor” and depolarized by outputs from L6 and L2. These links between layers are set in the script by network.link(…).
I hope this helps sheds more light, or leads to useful follow-ups at least.