Looking for advice.
It’s been very intriguing for me to learn about the specific property of SDRs: that despite the limited amount of bits (let’s say 20 out of 4000), the number of things it can uniquely represent is ginormous, given by the combination formula.
Expectation
In theory, different SDRs that are reusing some bit positions should never matter, because it’s the overall signal strength that matters (overlap will be very small).

For a concrete example, I’ve been trying to create a heteroassociative memory to remember “Hello world” string
INPUT = character position (layer #1, I generate different positions for each)
OUTPUT = SDR of the letter (layer #2)
Now, let’s say I have these input SDRs:
0th position → bits (23, 34, 45, 56)
1st position → bits (56, 67, 78, 89)
And I boost the connections from (23, 34, 45, 56) to SDR of the letter “H” in the output layer
…and (56, 67, 78, 89) to the letter “e”, and so on.
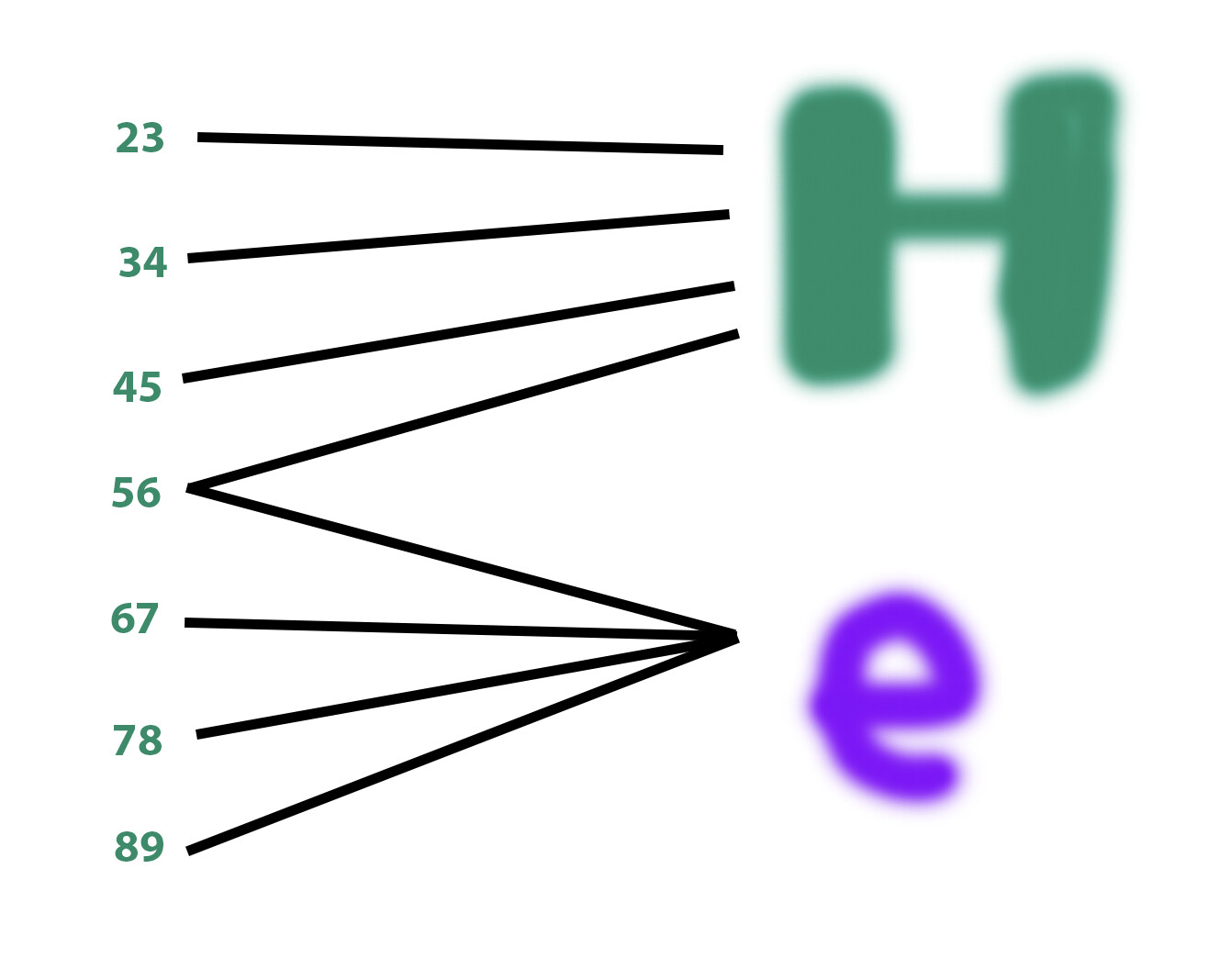
The theory says, it shouldn’t matter that 56 was accidentally selected to be used to encode both positions 0th and 1st
If 23, 34, 45 and 56 become set in the input layer at “inference” time, the signal to “e” will be so faint it’s almost non-existent, because the signal to “H” should overpower, so we get our “H” back correctly.
And of course, with more bit width of the SDR, the effect is even better. Which allows for all these crazy amount of combinations that all overlap with each other because of the limited amount of bits available, but every time we can recover the signal for the specific input because it will appear “brighter”, and the rest will be faint noise.
Reality
Here’s where the problem starts in practice, the one I’ve ran into. Let’s say some output letter in the text we’re trying to memorize is used more often than the rest - in practice, this pesky character turned out to be a space character.
Intuitively it should still be unclear why it would present a problem at this moment. But let’s consider the case where the bit level capacity = 200 bits to choose from, we choose 15 bits each time, and what happens after 1000 characters are stored.
Out of the 1000 characters, we encountered the space character, let’s say, 100 times (10% frequency). This means that for 100 different text positions (memory cells), which were assigned their all unique 15-bit SDRs, we boosted the connection from those bits to the space character SDR in the output layer. So now we had 100 positions * 15 bits = 1500 bit choices got connected to the space output SDR.
Of course, we don’t have 1500 input bits, we could only select them each time from the pool of 200, so each input bit 0…200 got ~7.5 boosts on average to the space character in the output layer.
Now, when we try to do “inference”, what happens?

Let’s consider again (23, 34, 45, 56…) SDR for 0th position. The letter expected is “H”
However, each of those input bits (23) (34) (45) (56)… separately, in the context of different unrelated input SDRs, got strongly connected to the space character with ~+7.5 weight, and only 1.0 to “H”
As a result, the output brightly highlights the SDR for the damn space almost every time! When I try to read back the text, it reads back space in almost every position.
Any thoughts on how this could be solved? I can obviously just make the output SDR be dependent on input SDR with hashing (so the SDR for “H” will also be different depending on the position), and I can even decode it back successfully - makes the memory almost perfect - but I don’t think that’s biologically plausible at all, where the output (some action, let’s say) has to be encoded differently, surely not. The closest I think I got to a candidate solution is pattern separation in hippocampus, but I don’t know if anyone tried something like this when applied to SDRs.
